CodeQL入门
前言
学学学,开始入坑静态代码扫描。
初步看下来应该是通过词法语法分析把代码分解成一个个具体的操作存进数据库里,后续要用来做什么就靠自己了。
安装
下载分析程序压缩包:https://github.com/github/codeql-cli-binaries/releases/latest/download/codeql.zip
下载编写QL脚本需要用到的库文件:https://github.com/Semmle/ql
参考文章里还用到了vscode扩展,在vscode里面搜索安装一下:
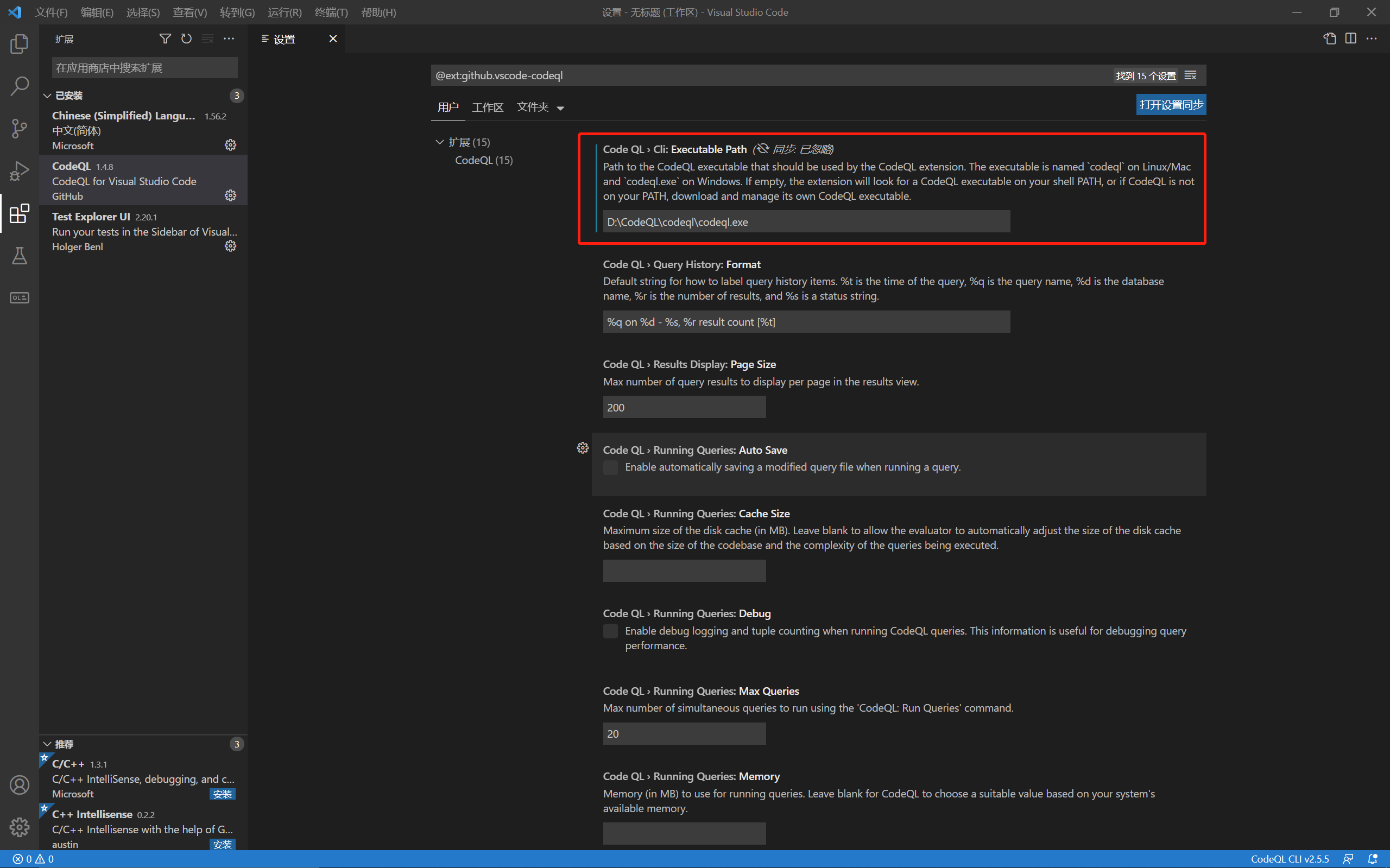
然后还要配置CodeQL可执行程序路径:
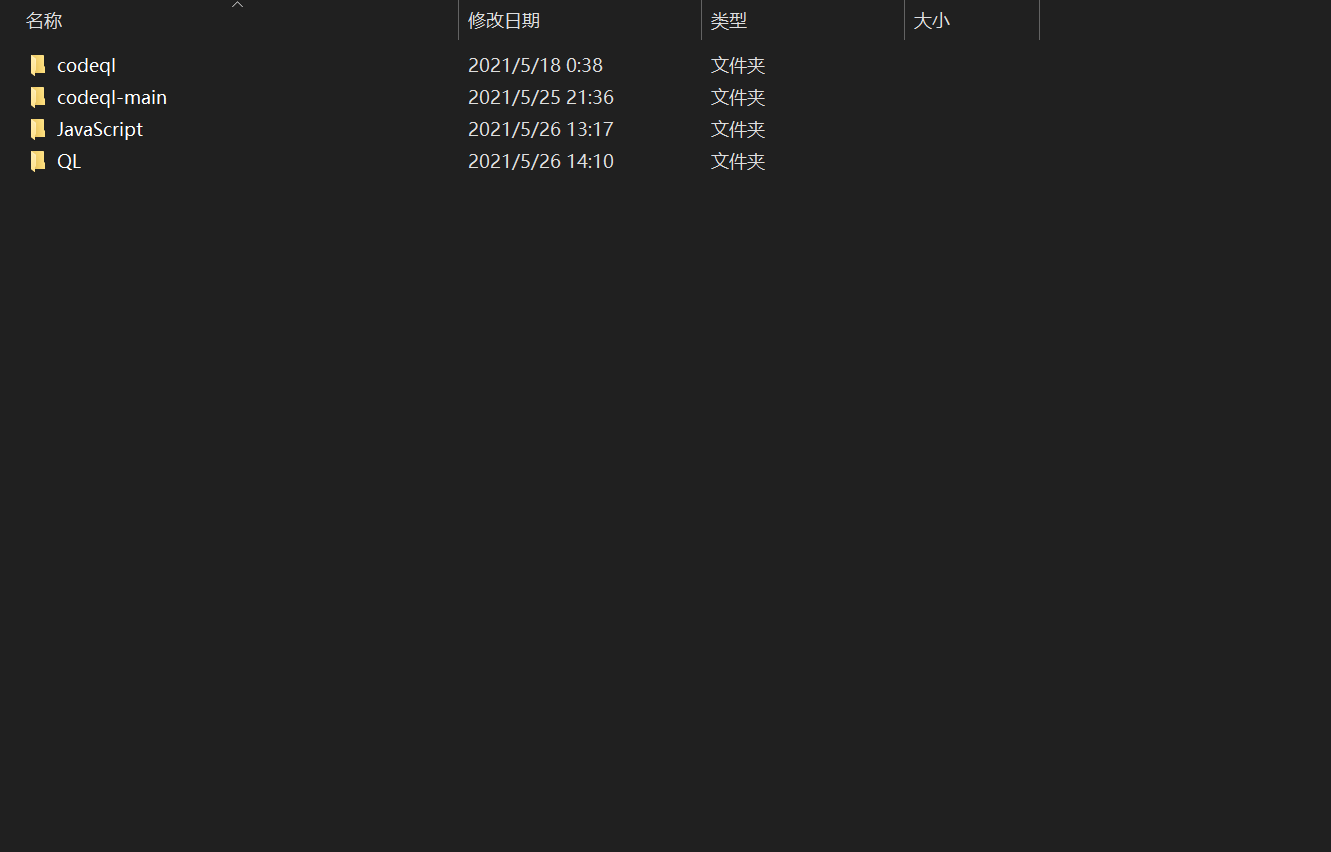
最后我的目录如下,分别是可执行程序目录、库目录、待分析代码目录及QL脚本目录:
体验
然后就开始体验使用CodeQL了,先写一个简单的JavaScript脚本,用于分析document.write这个函数调用:
1 | |
然后使用CodeQL分析并建立数据库:
1 | |
执行起来大概是这个样子的:
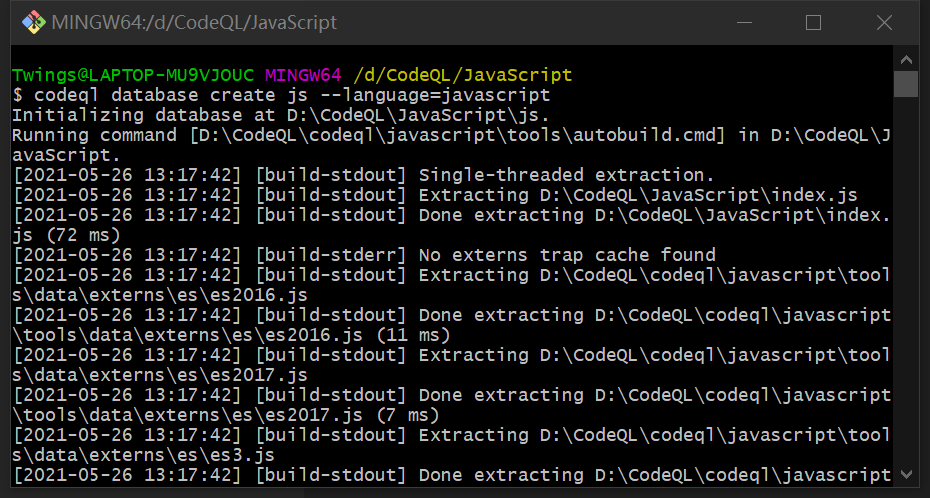
看起来除了要分析本身要分析的代码,还需要分析其他的库,完成后会生成一个数据库文件夹:
为了从数据库中查询我们需要的数据,需要编写QL脚本,简单写个来试试:
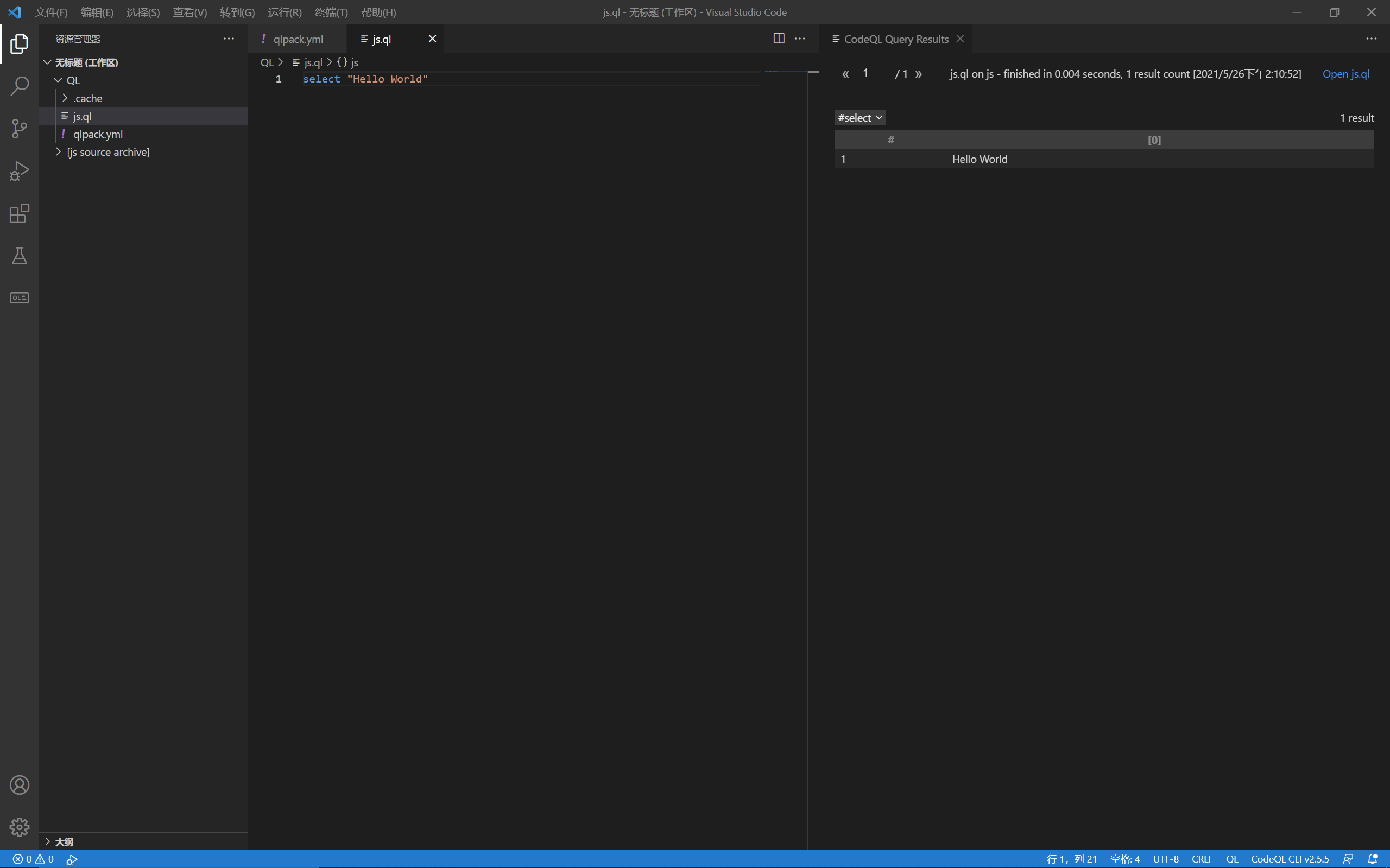
语法跟SQL类似,此时运行会遇到问题,说缺少qlpack.yml文件,官方文档里有介绍相关的东西,简单写一个:
1 | |
很奇怪的是,此时在QL脚本中import javascript可以导入到库目录下的文件,明明不管是CodeQL可执行程序的配置还是目录都不太相干,测试下来感觉像是QL扩展会自行进行搜索库文件夹,看起来会一级级网上找,具体不明。
QL脚本中的基础查询结构如下:
1 | |
对于各个子句的描述如下:
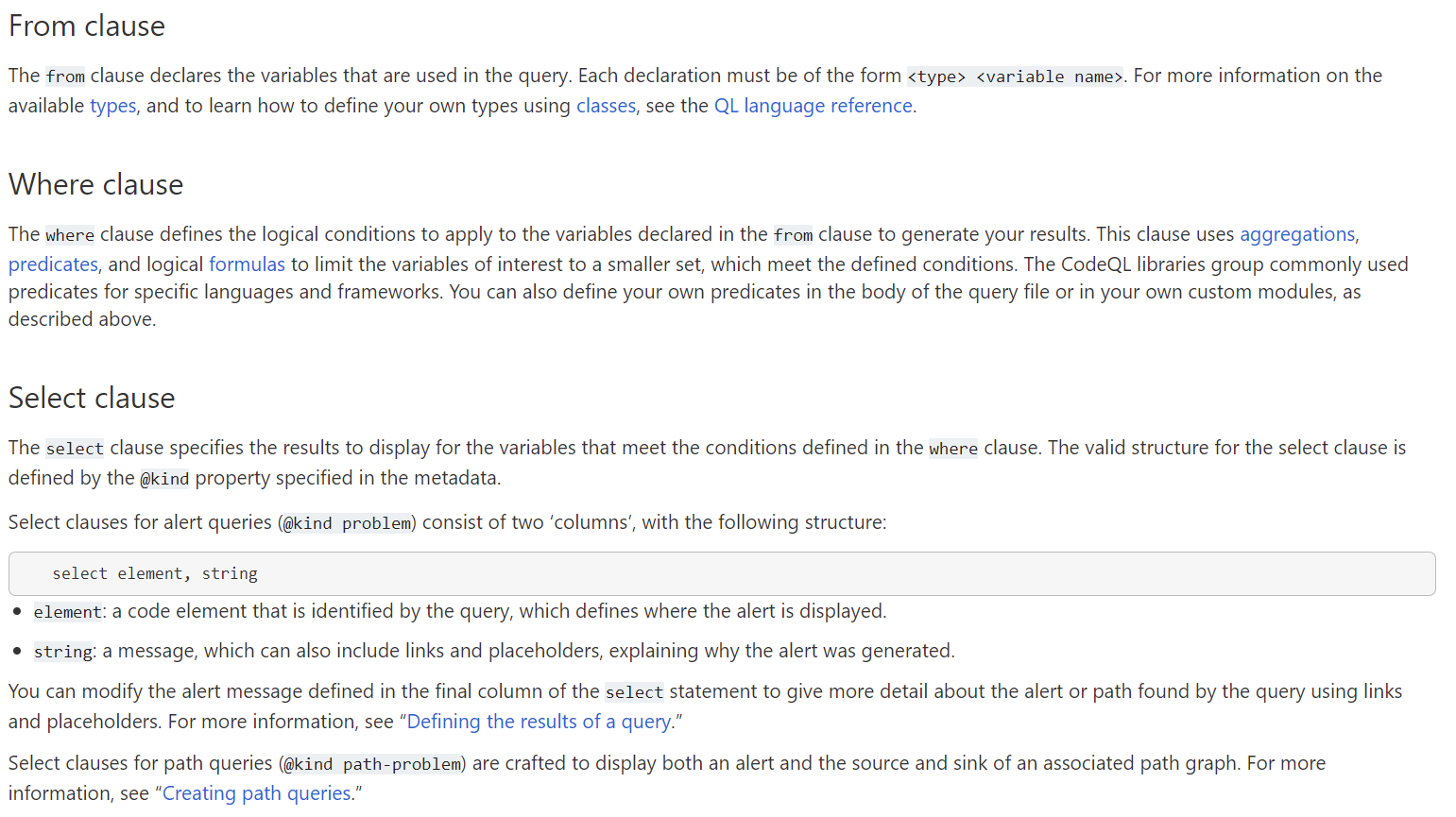
简单来说from定义要查询的数据(数据类型及变量名),where定义查询条件并且给变量赋值,select定义要显示的结果,再看看JavaScript里面常用的一些变量,比如函数调用相关的CallExpr:

继续查看文档,可以看到可以调用其getArgument函数获取参数相关信息:
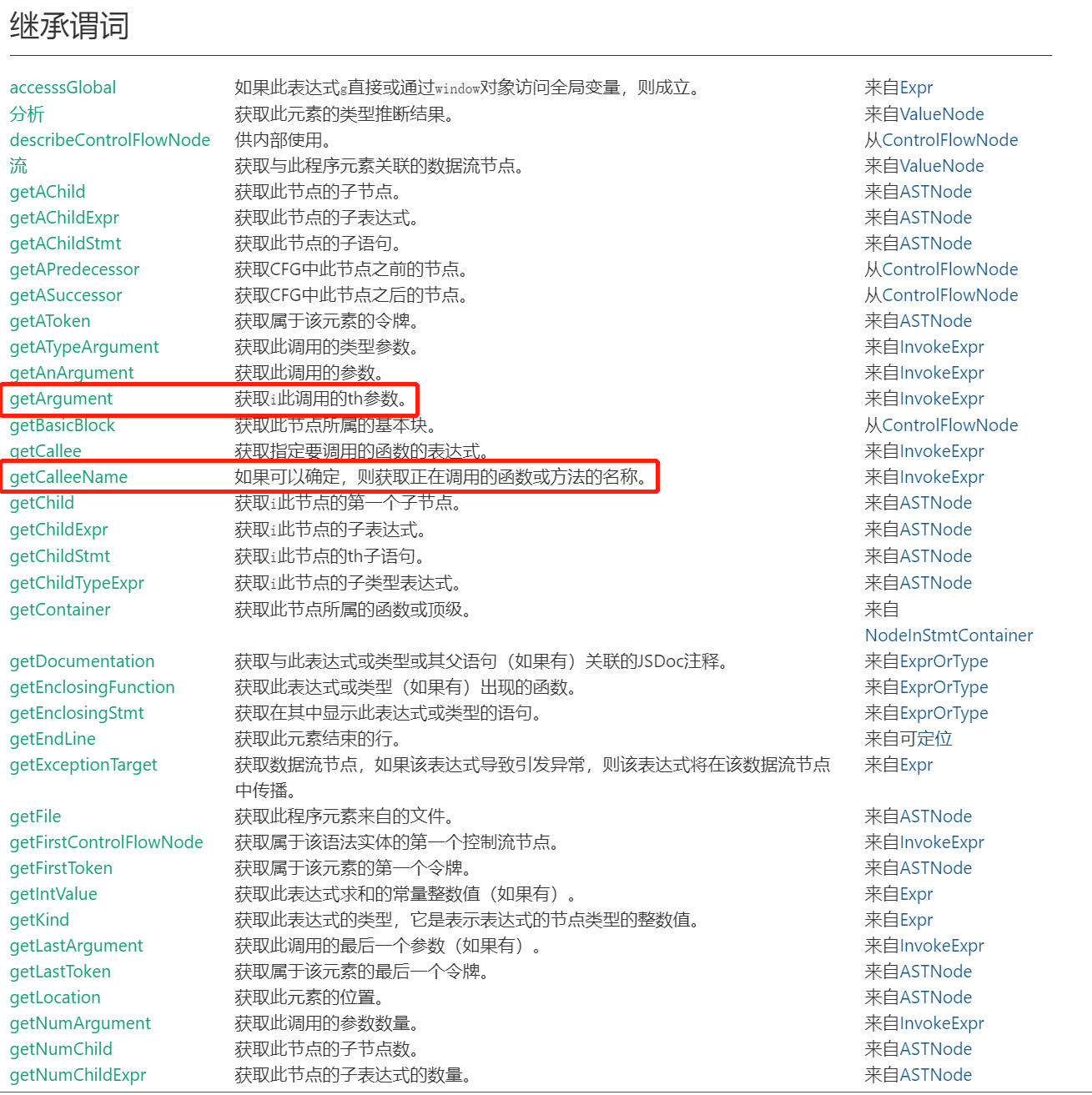
其返回值类型为Expr:

可以写出脚本:
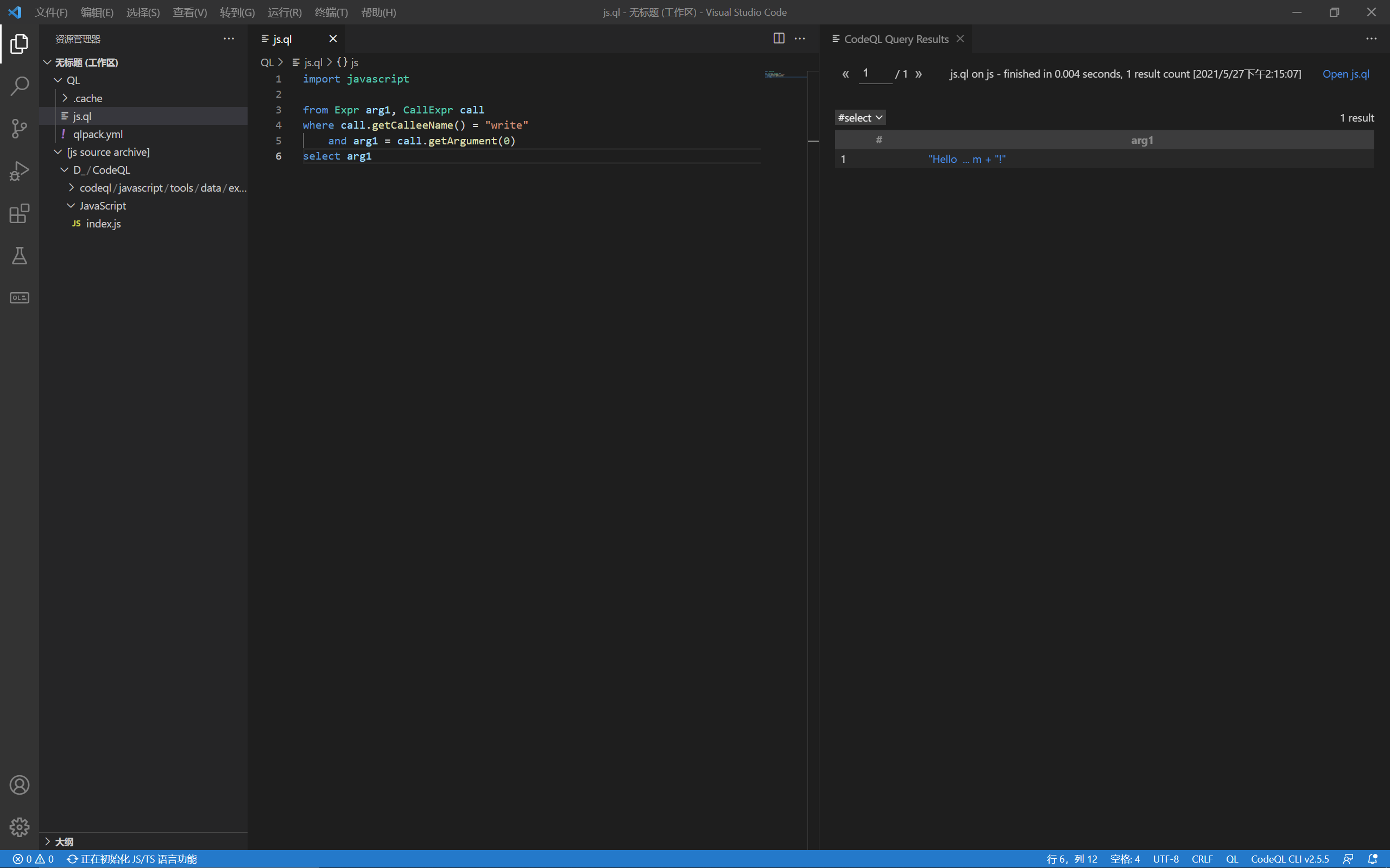
找到了函数调用及其参数后,我们还需要继续检查该参数从何而来,按照文档所说,可以用它的DataFlow库和TaintTracking库来查看数据流:

这里试着用用TaintTracking做污点追踪:
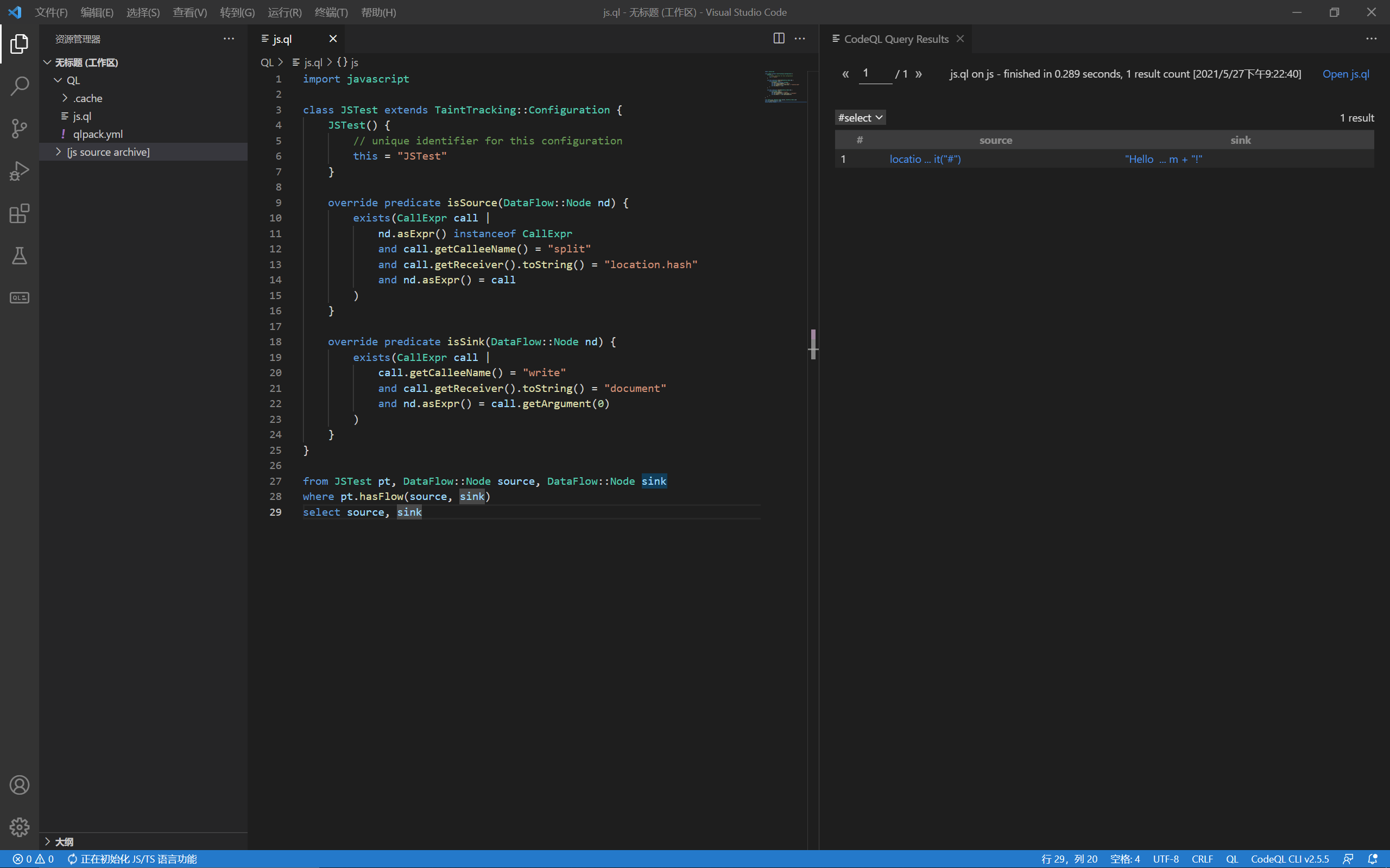
简单理解起来就是通过判断一个可控输入(source)和一个危险函数调用(sink)之间是否存在联系,这段代码的检查机制要求源头是一个location.hash.split函数调用的可控输入,终点是一个document.write的危险函数调用。
参考文章中给出的样本:
1 | |
稍微有点问题,这段代码会将params当成一个字符串处理,是无法进行XSS攻击的,稍微修改一下成:
1 | |
没问题:
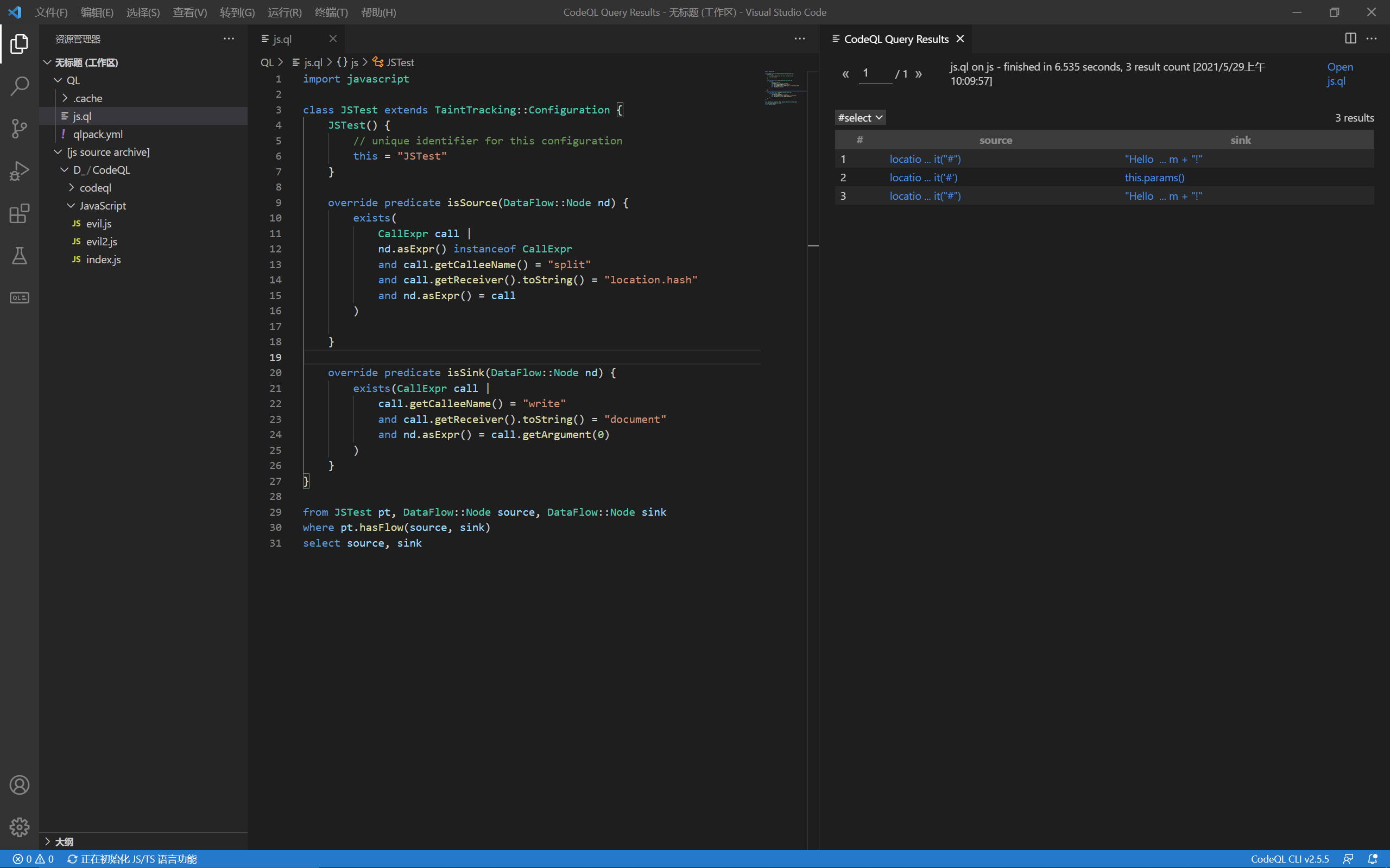
可能版本更新了,功能更强大了吧。