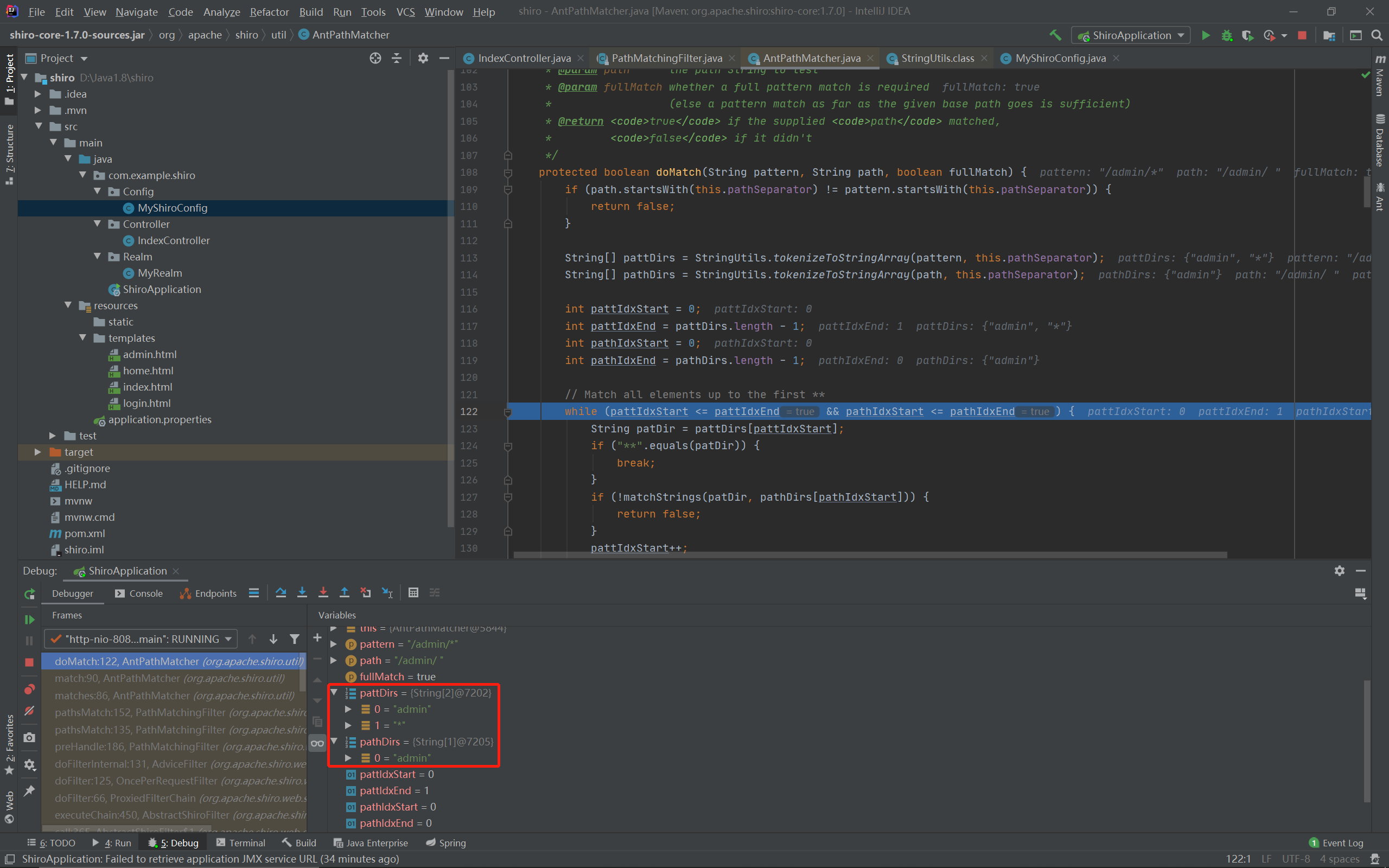
// Match all elements up to the first ** while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) { StringpatDir= pattDirs[pattIdxStart]; if ("**".equals(patDir)) { break; } if (!matchStrings(patDir, pathDirs[pathIdxStart])) { returnfalse; } pattIdxStart++; pathIdxStart++; }
if (pathIdxStart > pathIdxEnd) { // Path is exhausted, only match if rest of pattern is * or **'s if (pattIdxStart > pattIdxEnd) { return (pattern.endsWith(this.pathSeparator) ? path.endsWith(this.pathSeparator) : !path.endsWith(this.pathSeparator)); } if (!fullMatch) { returntrue; } if (pattIdxStart == pattIdxEnd && pattDirs[pattIdxStart].equals("*") && path.endsWith(this.pathSeparator)) { returntrue; } for (inti= pattIdxStart; i <= pattIdxEnd; i++) { if (!pattDirs[i].equals("**")) { returnfalse; } } returntrue; }
// Normalization if (normalize(req.decodedURI())) { // Character decoding convertURI(decodedURI, request); // Check that the URI is still normalized // Note: checkNormalize is deprecated because the test is no // longer required in Tomcat 10 onwards and has been // removed if (!checkNormalize(req.decodedURI())) { response.sendError(400, "Invalid URI"); } }
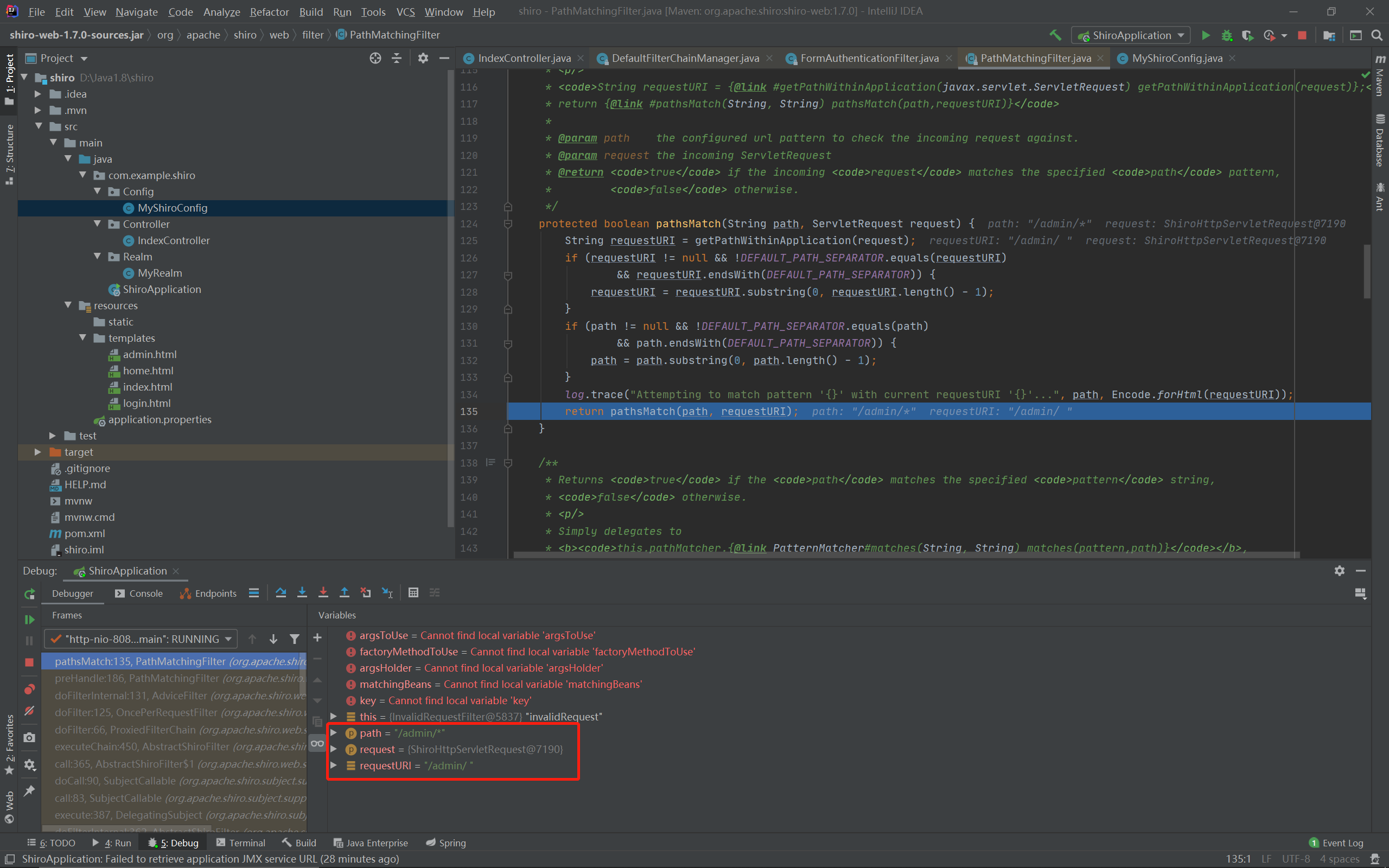
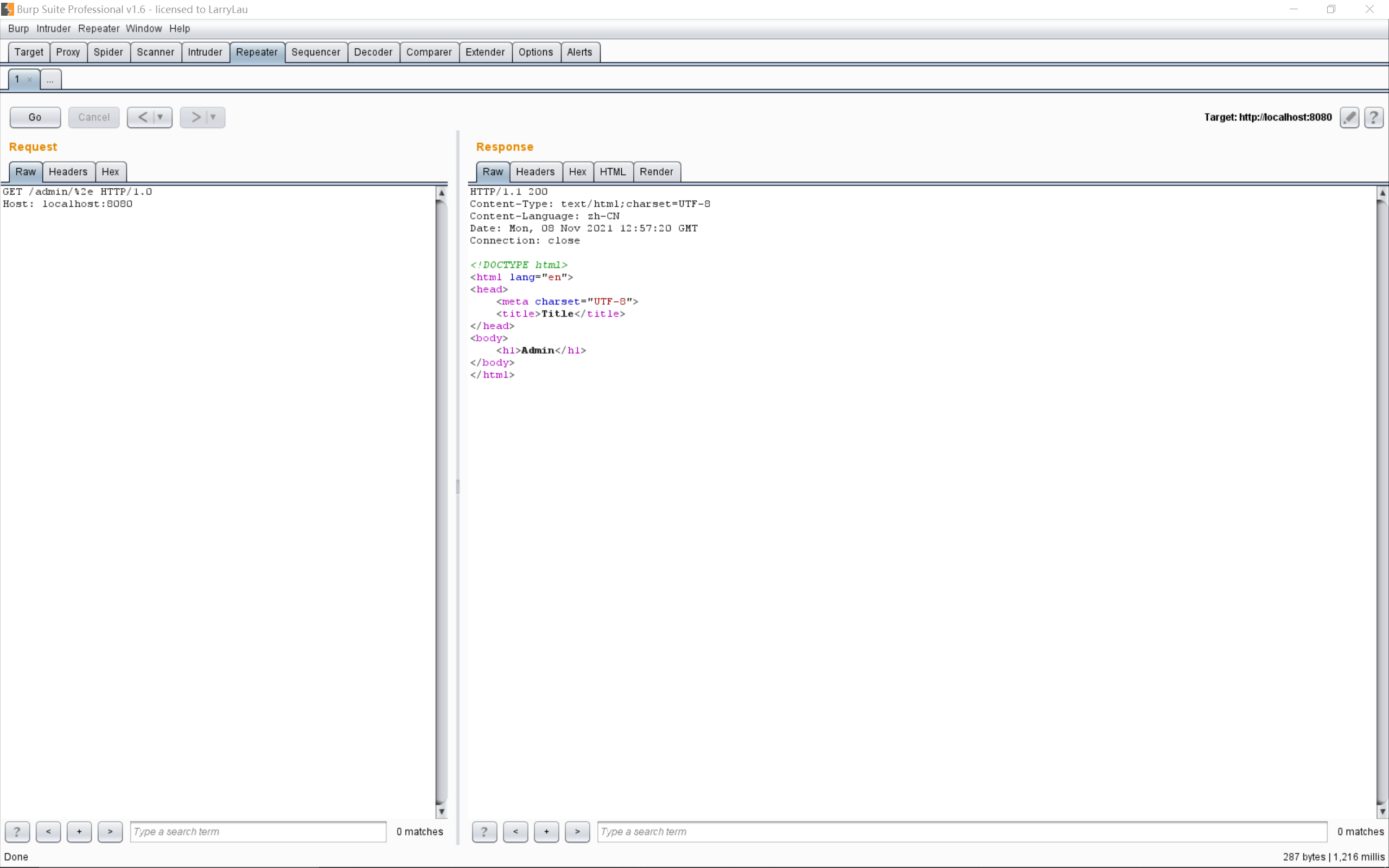
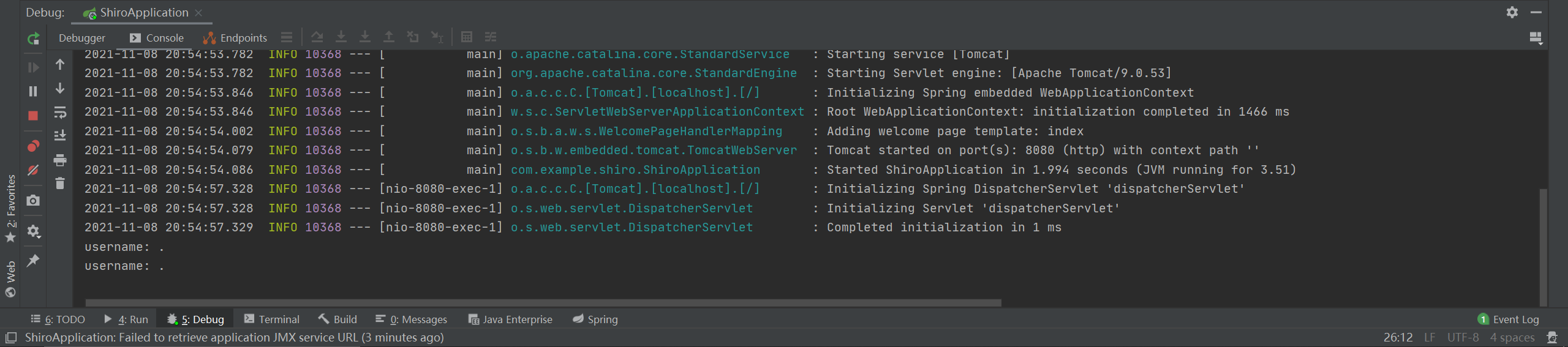
URI会经过normalize的标准化,后面的.就没了,变成了/admin/。
回到getChain函数,然后:
1 2 3 4 5 6 7
// in spring web, the requestURI "/resource/menus" ---- "resource/menus/" bose can access the resource // but the pathPattern match "/resource/menus" can not match "resource/menus/" // user can use requestURI + "/" to simply bypassed chain filter, to bypassed shiro protect if(requestURI != null && !DEFAULT_PATH_SEPARATOR.equals(requestURI) && requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) { requestURI = requestURI.substring(0, requestURI.length() - 1); }
去掉了末尾的/,变成了/admin,再到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
//the 'chain names' in this implementation are actually path patterns defined by the user. We just use them //as the chain name for the FilterChainManager's requirements for (String pathPattern : filterChainManager.getChainNames()) { if (pathPattern != null && !DEFAULT_PATH_SEPARATOR.equals(pathPattern) && pathPattern.endsWith(DEFAULT_PATH_SEPARATOR)) { pathPattern = pathPattern.substring(0, pathPattern.length() - 1); }
// If the path does match, then pass on to the subclass implementation for specific checks: if (pathMatches(pathPattern, requestURI)) { if (log.isTraceEnabled()) { log.trace("Matched path pattern [" + pathPattern + "] for requestURI [" + Encode.forHtml(requestURI) + "]. " + "Utilizing corresponding filter chain..."); } return filterChainManager.proxy(originalChain, pathPattern); } }
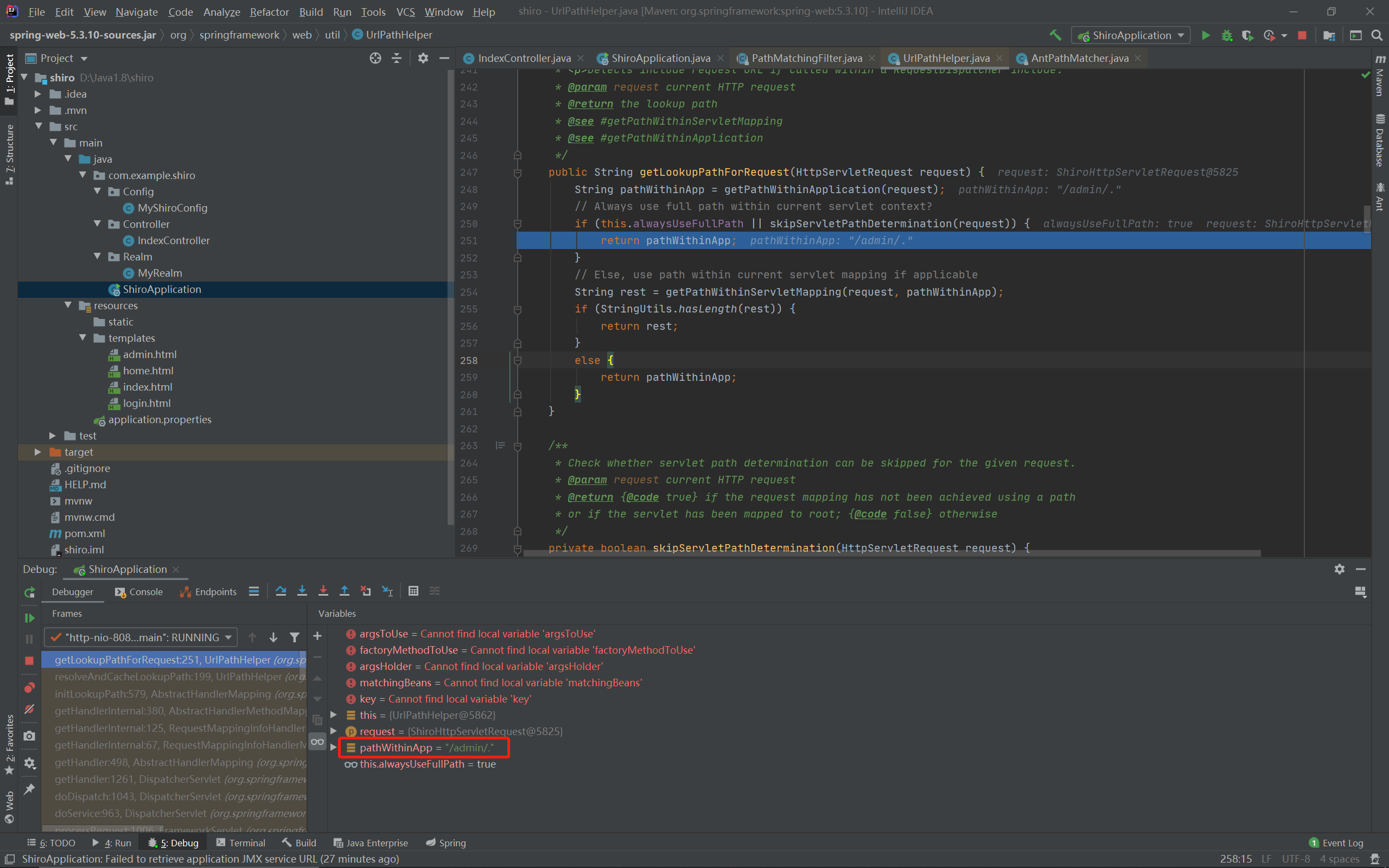
public String getLookupPathForRequest(HttpServletRequest request) { StringpathWithinApp= getPathWithinApplication(request); // Always use full path within current servlet context? if (this.alwaysUseFullPath || skipServletPathDetermination(request)) { return pathWithinApp; } // Else, use path within current servlet mapping if applicable Stringrest= getPathWithinServletMapping(request, pathWithinApp); if (StringUtils.hasLength(rest)) { return rest; } else { return pathWithinApp; } }
正如注释所说,Always use full path,也就不用特地做设置了,此时会将整个path即/admin/.返回:
//the 'chain names' in this implementation are actually path patterns defined by the user. We just use them //as the chain name for the FilterChainManager's requirements for (String pathPattern : filterChainManager.getChainNames()) { ... }
// in spring web, the requestURI "/resource/menus" ---- "resource/menus/" bose can access the resource // but the pathPattern match "/resource/menus" can not match "resource/menus/" // user can use requestURI + "/" to simply bypassed chain filter, to bypassed shiro protect
pathPattern = removeTrailingSlash(pathPattern);
if (pathMatches(pathPattern, requestURINoTrailingSlash)) { ... return filterChainManager.proxy(originalChain, requestURINoTrailingSlash); } }
log.trace("Attempting to match pattern '{}' with current requestURI '{}'...", path, Encode.forHtml(requestURI)); booleanmatch= pathsMatch(path, requestURI);
也是删掉了去掉末尾/的部分代码,同样也有去掉末尾/之后再试一次:
1 2 3 4 5 6 7 8 9 10 11 12
if (!match) { if (requestURI != null && !DEFAULT_PATH_SEPARATOR.equals(requestURI) && requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) { requestURI = requestURI.substring(0, requestURI.length() - 1); } if (path != null && !DEFAULT_PATH_SEPARATOR.equals(path) && path.endsWith(DEFAULT_PATH_SEPARATOR)) { path = path.substring(0, path.length() - 1); } log.trace("Attempting to match pattern '{}' with current requestURI '{}'...", path, Encode.forHtml(requestURI)); match = pathsMatch(path, requestURI); }