前言
SHIRO-721的Padding Oracle攻击太麻烦了,知道个原理就算了,接下来学习一下Shiro认证绕过的漏洞。
环境搭建
要求版本:Shiro<1.7.1。
首先要配置一个包含通配符的,要求认证的路径:
map.put("/admin/*", "authc");
再在springboot中配置一个符合该路径的资源:
@RequestMapping("/admin/{username}")
public String admin(@PathVariable String username) {
System.out.println("username: " + URLEncoder.encode(username));
return "admin";
}
这种情况下如果访问/admin/admin之类的路径,就会被重定向至index界面。
访问/admin/不会进行认证,但是会返回404。
空格绕过
访问/admin/%20可以绕过认证直接访问到spring中的admin路径,进行路径匹配的点主要有两个,不那么关键的点在于PathMatchingFilter类的pathsMatch函数:
protected boolean pathsMatch(String path, ServletRequest request) {
String requestURI = getPathWithinApplication(request);
if (requestURI != null && !DEFAULT_PATH_SEPARATOR.equals(requestURI)
&& requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) {
requestURI = requestURI.substring(0, requestURI.length() - 1);
}
if (path != null && !DEFAULT_PATH_SEPARATOR.equals(path)
&& path.endsWith(DEFAULT_PATH_SEPARATOR)) {
path = path.substring(0, path.length() - 1);
}
log.trace("Attempting to match pattern '{}' with current requestURI '{}'...", path, Encode.forHtml(requestURI));
return pathsMatch(path, requestURI);
}
第一段lf去掉请求路径末尾的/,第二段if去掉配置的认证路径末尾的/,完成后:
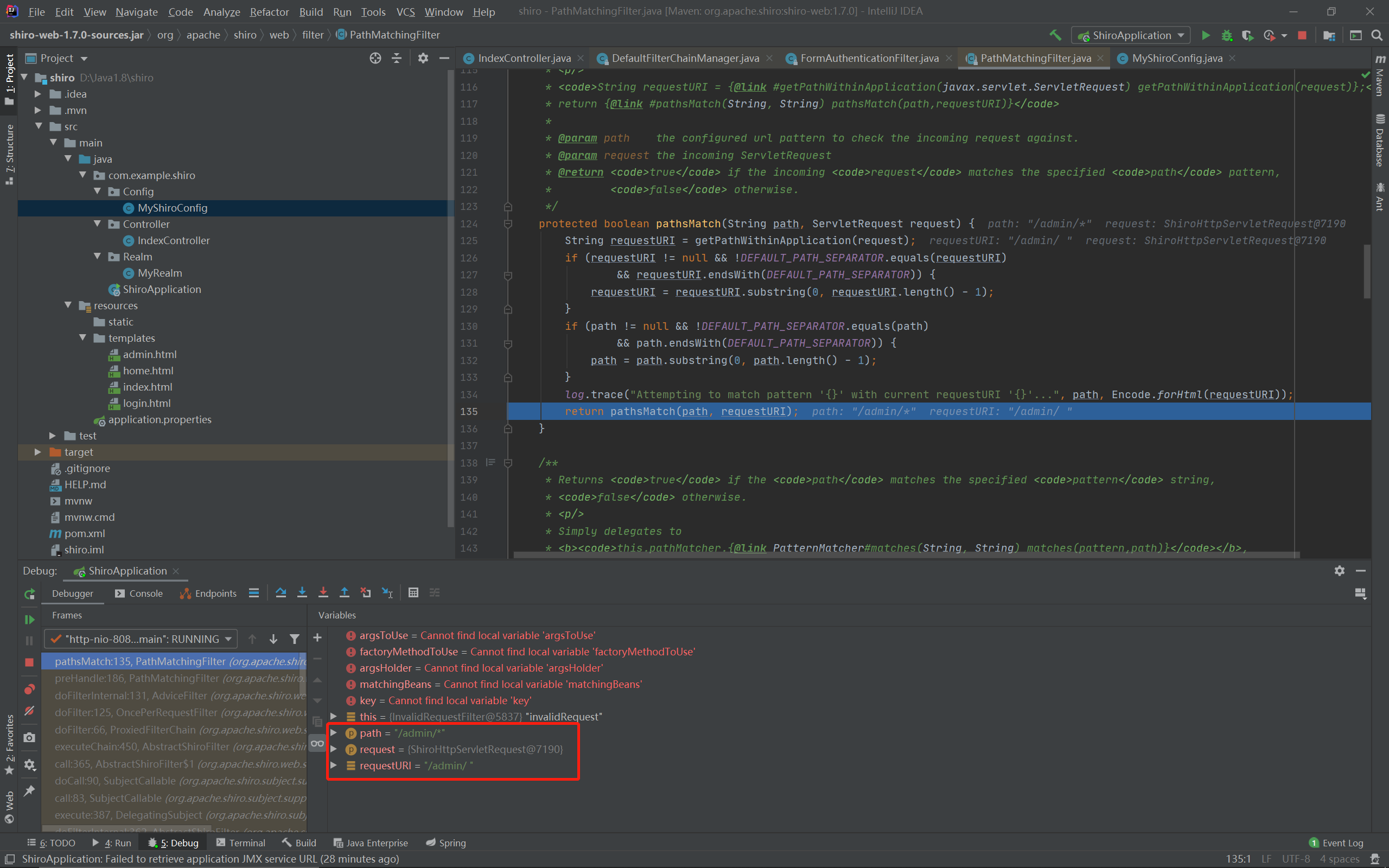
最后调用了另一个pathsMatch函数:
protected PatternMatcher pathMatcher = new AntPathMatcher();
protected boolean pathsMatch(String pattern, String path) {
return pathMatcher.matches(pattern, path);
}
即AntPathMatcher的matches函数,然后来到其doMatch函数中,这个函数很长:
String[] pattDirs = StringUtils.tokenizeToStringArray(pattern, this.pathSeparator);
String[] pathDirs = StringUtils.tokenizeToStringArray(path, this.pathSeparator);
首先是将pattern和path按照/切割成字符串数组,但是我们观察切割后的结果:
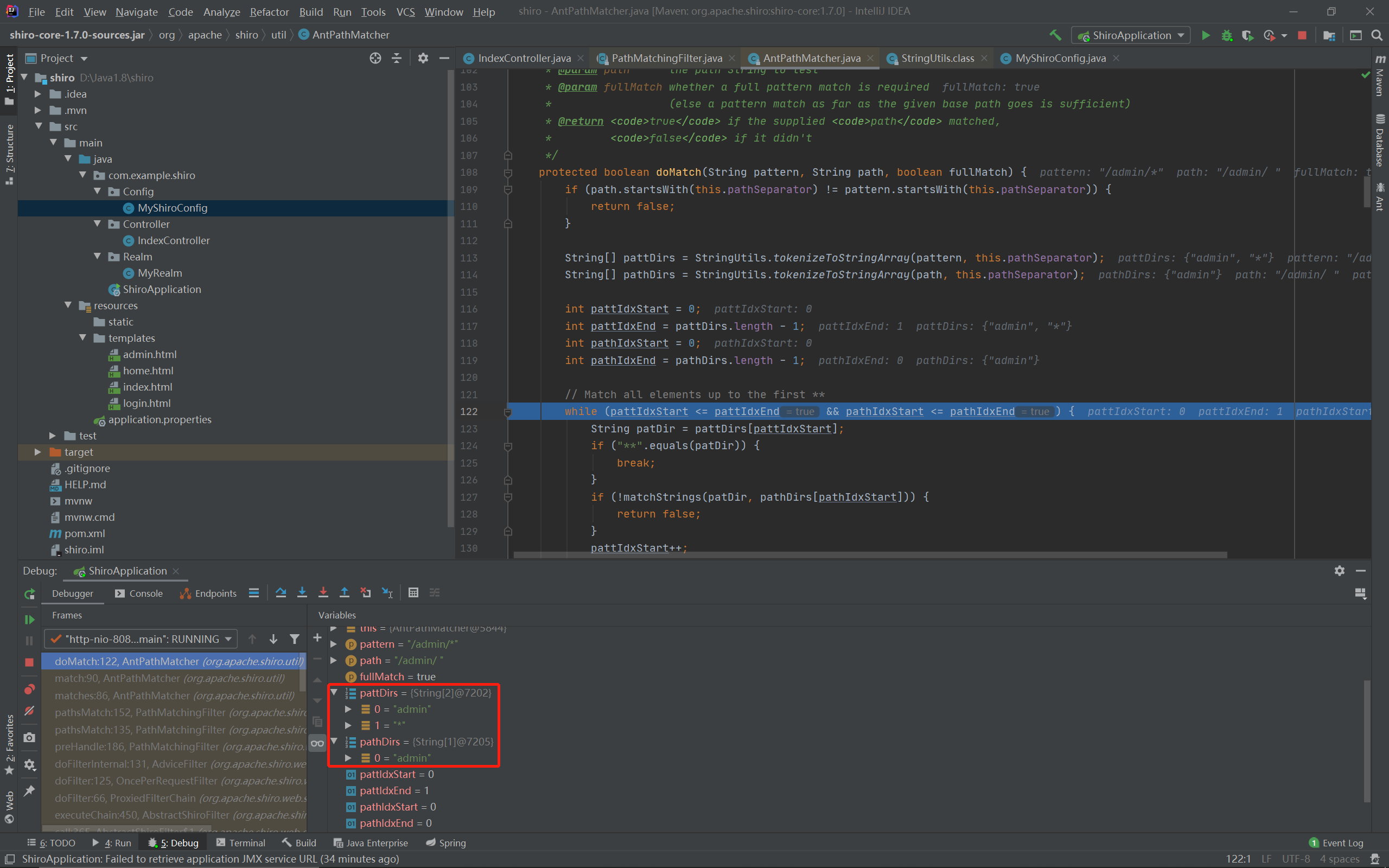
可以看到path中的空格被舍弃了,只剩下了前面admin的部分,我们去看看StringUtils.tokenizeToStringArray函数究竟做了什么:
public static String[] tokenizeToStringArray(String str, String delimiters) {
return tokenizeToStringArray(str, delimiters, true, true);
}
public static String[] tokenizeToStringArray(String str, String delimiters, boolean trimTokens, boolean ignoreEmptyTokens) {
if (str == null) {
return null;
} else {
StringTokenizer st = new StringTokenizer(str, delimiters);
ArrayList tokens = new ArrayList();
while(true) {
String token;
do {
if (!st.hasMoreTokens()) {
return toStringArray(tokens);
}
token = st.nextToken();
if (trimTokens) {
token = token.trim();
}
} while(ignoreEmptyTokens && token.length() <= 0);
tokens.add(token);
}
}
}
StringTokenizer类是Java内部的字符串分割类,关键点在循环中,当trimTokens为true时会调用trim函数,而trimTokens来自参数,是一个写死的true,所以当循环到我们输入的空格时,trim函数就会调用,将字符串头尾空白字符删除。而因为该段字符串只有一个空格,最后就什么都不剩下了。
回到doMatch函数中:
// Match all elements up to the first **
while (pattIdxStart <= pattIdxEnd && pathIdxStart <= pathIdxEnd) {
String patDir = pattDirs[pattIdxStart];
if ("**".equals(patDir)) {
break;
}
if (!matchStrings(patDir, pathDirs[pathIdxStart])) {
return false;
}
pattIdxStart++;
pathIdxStart++;
}
因为pattDirs有admin和通配符两个部分,而pathDirs只剩下前半的admin,所以第一部分匹配成功后就会因为pathDirs已经遍历完而退出这段循环,看下一段代码:
if (pathIdxStart > pathIdxEnd) {
// Path is exhausted, only match if rest of pattern is * or **'s
if (pattIdxStart > pattIdxEnd) {
return (pattern.endsWith(this.pathSeparator) ?
path.endsWith(this.pathSeparator) : !path.endsWith(this.pathSeparator));
}
if (!fullMatch) {
return true;
}
if (pattIdxStart == pattIdxEnd && pattDirs[pattIdxStart].equals("*") &&
path.endsWith(this.pathSeparator)) {
return true;
}
for (int i = pattIdxStart; i <= pattIdxEnd; i++) {
if (!pattDirs[i].equals("**")) {
return false;
}
}
return true;
}
当path被匹配完时会进入这段代码,因为pattern没有匹配完不会进入第一个判断,因为fullMatch来自参数而且为true不会进入第二个判断,因为path不是以/结尾不会进入第三个判断,最后因为pattern是*不是**会返回false。
上面说的不那么关键的点只是用来确认filter链要不要继续执行,比较关键的点在于之前获取要执行的filter链,即PathMatchingFilterChainResolver类的getChain函数:
public FilterChain getChain(ServletRequest request, ServletResponse response, FilterChain originalChain) {
FilterChainManager filterChainManager = getFilterChainManager();
if (!filterChainManager.hasChains()) {
return null;
}
String requestURI = getPathWithinApplication(request);
...
return null;
}
首先通过getPathWithinApplication函数获取URI:
public static String getPathWithinApplication(HttpServletRequest request) {
return normalize(removeSemicolon(getServletPath(request) + getPathInfo(request)));
}
这里会通过normalize函数将路径标准化,将一些相关字符去掉,比如//和/.之类的。
不过调试可以发现,.的去除跟normalize函数无关,而是getPathInfo的返回值为空字符串,同时还发现当访问/admin/123123时getPathInfo的返回值同样为空字符串,123123的部分会在getServletPath函数返回,不懂这个属性有什么用的。
往上看到tomcat的部分可以看到:
// Normalization
if (normalize(req.decodedURI())) {
// Character decoding
convertURI(decodedURI, request);
// Check that the URI is still normalized
// Note: checkNormalize is deprecated because the test is no
// longer required in Tomcat 10 onwards and has been
// removed
if (!checkNormalize(req.decodedURI())) {
response.sendError(400, "Invalid URI");
}
}
URI会经过normalize的标准化,后面的.就没了,变成了/admin/。
回到getChain函数,然后:
// in spring web, the requestURI "/resource/menus" ---- "resource/menus/" bose can access the resource
// but the pathPattern match "/resource/menus" can not match "resource/menus/"
// user can use requestURI + "/" to simply bypassed chain filter, to bypassed shiro protect
if(requestURI != null && !DEFAULT_PATH_SEPARATOR.equals(requestURI)
&& requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) {
requestURI = requestURI.substring(0, requestURI.length() - 1);
}
去掉了末尾的/,变成了/admin,再到:
//the 'chain names' in this implementation are actually path patterns defined by the user. We just use them
//as the chain name for the FilterChainManager's requirements
for (String pathPattern : filterChainManager.getChainNames()) {
if (pathPattern != null && !DEFAULT_PATH_SEPARATOR.equals(pathPattern)
&& pathPattern.endsWith(DEFAULT_PATH_SEPARATOR)) {
pathPattern = pathPattern.substring(0, pathPattern.length() - 1);
}
// If the path does match, then pass on to the subclass implementation for specific checks:
if (pathMatches(pathPattern, requestURI)) {
if (log.isTraceEnabled()) {
log.trace("Matched path pattern [" + pathPattern + "] for requestURI [" + Encode.forHtml(requestURI) + "]. " +
"Utilizing corresponding filter chain...");
}
return filterChainManager.proxy(originalChain, pathPattern);
}
}
遍历配置的pattern,通过pathMatches函数确定哪些filter是要调用的:
protected boolean pathMatches(String pattern, String path) {
PatternMatcher pathMatcher = getPathMatcher();
return pathMatcher.matches(pattern, path);
}
pathMatcher同样是个AntPathMatcher,后面的匹配流程就跟前面所说的一致了:
public PathMatchingFilterChainResolver() {
this.pathMatcher = new AntPathMatcher();
this.filterChainManager = new DefaultFilterChainManager();
}
public PathMatchingFilterChainResolver(FilterConfig filterConfig) {
this.pathMatcher = new AntPathMatcher();
this.filterChainManager = new DefaultFilterChainManager(filterConfig);
}
public PatternMatcher getPathMatcher() {
return pathMatcher;
}
最后到了spring中,这个空格就会作为参数被赋值到参数中:
/./绕过
听说首先要开启spring中的全路径,不然会影响spring的路径匹配,具体开启方法可以看这里。
不过我这里好像不用开启也可以正常访问:
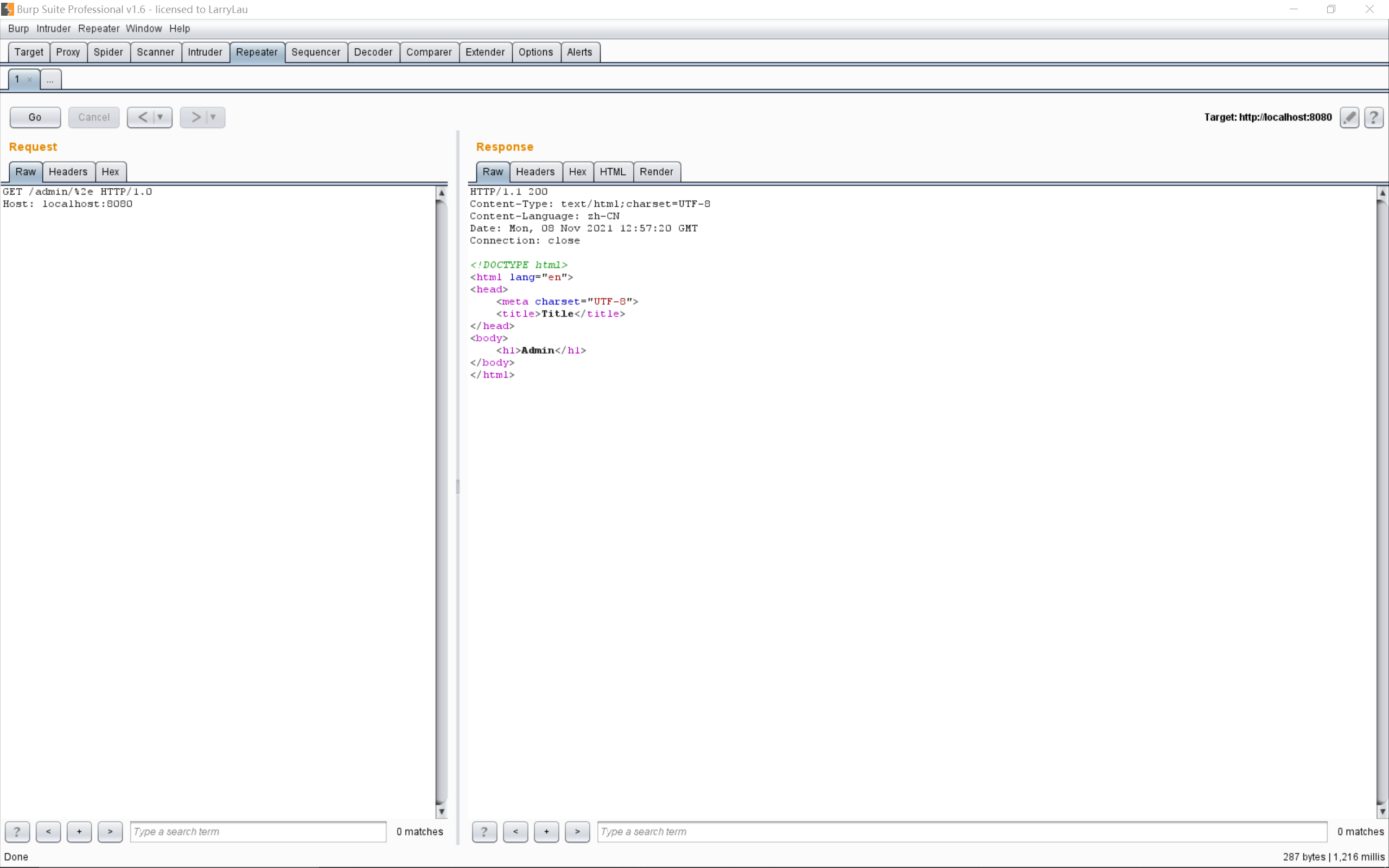
.同样被作为了参数:
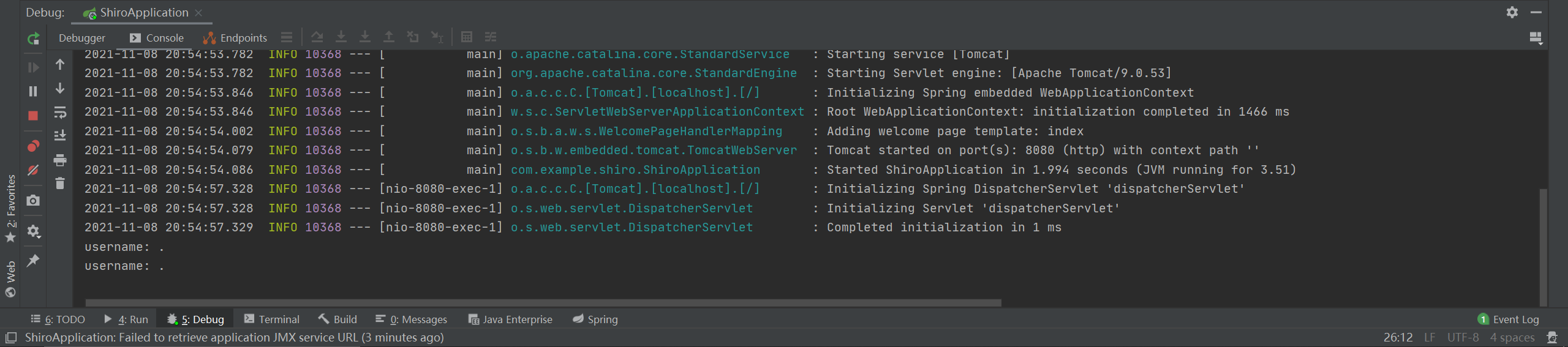
通过调试可以发现,我环境下的alwaysUseFullPath在初始化时就赋值为了true,找一下setAlwaysUseFullPath函数的调用路径:
// AbstractHandlerMapping
public void setAlwaysUseFullPath(boolean alwaysUseFullPath) {
this.urlPathHelper.setAlwaysUseFullPath(alwaysUseFullPath);
if (this.corsConfigurationSource instanceof UrlBasedCorsConfigurationSource) {
((UrlBasedCorsConfigurationSource) this.corsConfigurationSource).setAlwaysUseFullPath(alwaysUseFullPath);
}
}
// UrlBasedCorsConfigurationSource
@Deprecated
public void setAlwaysUseFullPath(boolean alwaysUseFullPath) {
initUrlPathHelper();
this.urlPathHelper.setAlwaysUseFullPath(alwaysUseFullPath);
}
可以看到不管怎么样最后调用的都是urlPathHelper的setAlwaysUseFullPath函数:
public void setAlwaysUseFullPath(boolean alwaysUseFullPath) {
checkReadOnly();
this.alwaysUseFullPath = alwaysUseFullPath;
}
最后放入alwaysUseFullPath属性中,在后续访问中会通过调用getLookupPathForRequest函数来访问该属性:
public String getLookupPathForRequest(HttpServletRequest request) {
String pathWithinApp = getPathWithinApplication(request);
// Always use full path within current servlet context?
if (this.alwaysUseFullPath || skipServletPathDetermination(request)) {
return pathWithinApp;
}
// Else, use path within current servlet mapping if applicable
String rest = getPathWithinServletMapping(request, pathWithinApp);
if (StringUtils.hasLength(rest)) {
return rest;
}
else {
return pathWithinApp;
}
}
正如注释所说,Always use full path,也就不用特地做设置了,此时会将整个path即/admin/.返回:
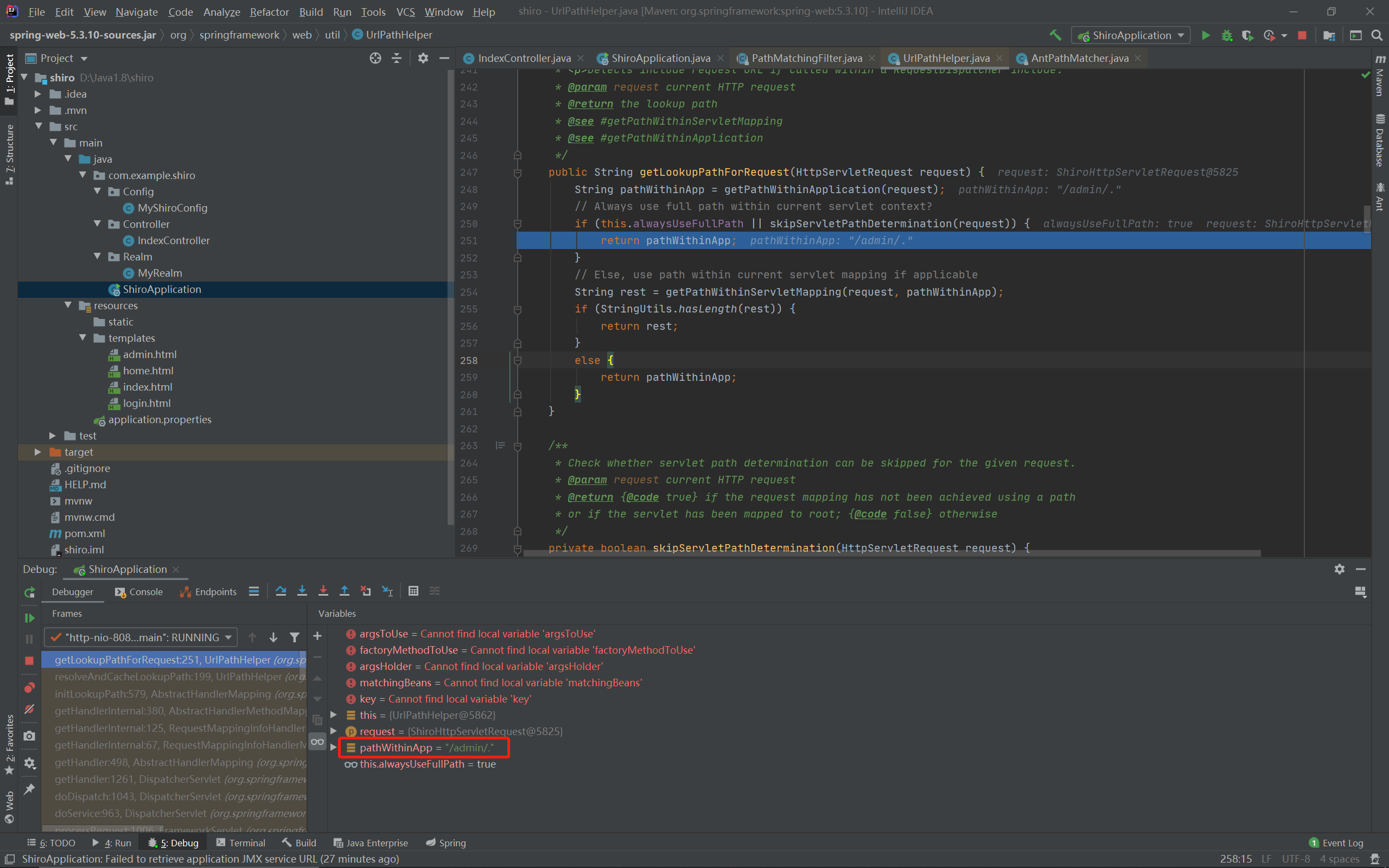
调用栈如下:
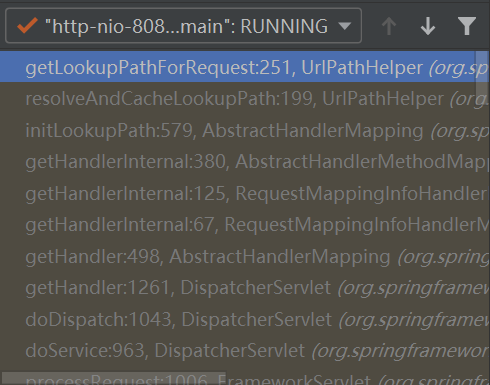
往上回到resolveAndCacheLookupPath函数:
public String resolveAndCacheLookupPath(HttpServletRequest request) {
String lookupPath = getLookupPathForRequest(request);
request.setAttribute(PATH_ATTRIBUTE, lookupPath);
return lookupPath;
}
将获取到的路径即/admin/.放入request中,再往上回到getHandlerInternal函数:
protected HandlerMethod getHandlerInternal(HttpServletRequest request) throws Exception {
String lookupPath = initLookupPath(request);
this.mappingRegistry.acquireReadLock();
try {
HandlerMethod handlerMethod = lookupHandlerMethod(lookupPath, request);
return (handlerMethod != null ? handlerMethod.createWithResolvedBean() : null);
}
finally {
this.mappingRegistry.releaseReadLock();
}
}
根据访问路径查取处理函数,进入lookupHandlerMethod函数,一步步来到getMatchingCondition函数:
PatternsRequestCondition patterns = null;
if (this.patternsCondition != null) {
patterns = this.patternsCondition.getMatchingCondition(request);
if (patterns == null) {
return null;
}
}
这里存在patternsCondition条件,进入getMatchingCondition函数进行匹配:
public PatternsRequestCondition getMatchingCondition(HttpServletRequest request) {
String lookupPath = UrlPathHelper.getResolvedLookupPath(request);
List<String> matches = getMatchingPatterns(lookupPath);
return !matches.isEmpty() ? new PatternsRequestCondition(new LinkedHashSet<>(matches), this) : null;
}
// UrlPathHelper
public static String getResolvedLookupPath(ServletRequest request) {
String lookupPath = (String) request.getAttribute(PATH_ATTRIBUTE);
Assert.notNull(lookupPath, "Expected lookupPath in request attribute \"" + PATH_ATTRIBUTE + "\".");
return lookupPath;
}
从request中取出了之前存入的/admin/.,接下来就是正则匹配了,此时的正则规则为:
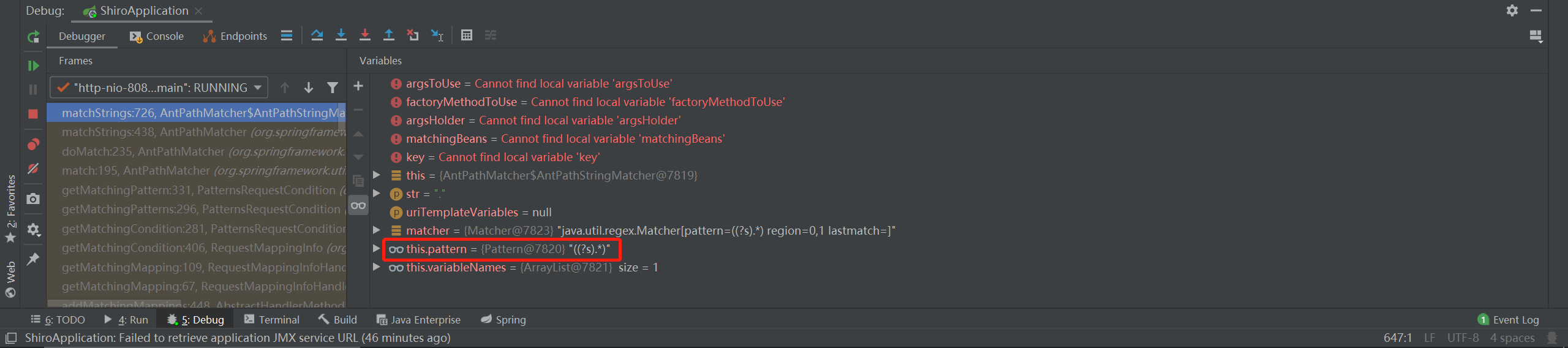
?s表示单行匹配,让.能匹配换行符,简单来说就是基本什么字符都行。
spring的部分看完了,shiro的部分就不用看了,问题就出在tomcat通过normalize函数标准化了URI。
修复方式
空格
调用StringUtils.tokenizeToStringArray函数时:
String[] pattDirs = StringUtils.tokenizeToStringArray(pattern, this.pathSeparator, false, true);
String[] pathDirs = StringUtils.tokenizeToStringArray(path, this.pathSeparator, false, true);
将trimTokens设置为了false,不会再调用trim去除空白字符了。
/./
两个点都做了修复,在PathMatchingFilterChainResolver类的getChain函数中:
final String requestURI = getPathWithinApplication(request);
final String requestURINoTrailingSlash = removeTrailingSlash(requestURI);
//the 'chain names' in this implementation are actually path patterns defined by the user. We just use them
//as the chain name for the FilterChainManager's requirements
for (String pathPattern : filterChainManager.getChainNames()) {
...
}
少了去掉末尾/的环节,这样到了doMatch函数中就会因为path被匹配完,且末尾存在/而返回true。不仅如此,如果没去掉末尾/的路径匹配失败,还会用去掉末尾/的路径再试一次:
if (pathMatches(pathPattern, requestURI)) {
...
return filterChainManager.proxy(originalChain, pathPattern);
} else {
// in spring web, the requestURI "/resource/menus" ---- "resource/menus/" bose can access the resource
// but the pathPattern match "/resource/menus" can not match "resource/menus/"
// user can use requestURI + "/" to simply bypassed chain filter, to bypassed shiro protect
pathPattern = removeTrailingSlash(pathPattern);
if (pathMatches(pathPattern, requestURINoTrailingSlash)) {
...
return filterChainManager.proxy(originalChain, requestURINoTrailingSlash);
}
}
而在PathMatchingFilter的pathsMatch函数中也一样:
String requestURI = getPathWithinApplication(request);
log.trace("Attempting to match pattern '{}' with current requestURI '{}'...", path, Encode.forHtml(requestURI));
boolean match = pathsMatch(path, requestURI);
也是删掉了去掉末尾/的部分代码,同样也有去掉末尾/之后再试一次:
if (!match) {
if (requestURI != null && !DEFAULT_PATH_SEPARATOR.equals(requestURI)
&& requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) {
requestURI = requestURI.substring(0, requestURI.length() - 1);
}
if (path != null && !DEFAULT_PATH_SEPARATOR.equals(path)
&& path.endsWith(DEFAULT_PATH_SEPARATOR)) {
path = path.substring(0, path.length() - 1);
}
log.trace("Attempting to match pattern '{}' with current requestURI '{}'...", path, Encode.forHtml(requestURI));
match = pathsMatch(path, requestURI);
}