trainRatio = 0.7 myMat, labels = file2matrix("E:/dataSet/kNN/wine.data") myMat = autoNorm(myMat) index = 0 trainIndex = 0 testIndex = 0 rowNumber = myMat.shape[0] trainMat = zeros((rowNumber, 13)) trainLabels = [] testMat = zeros((rowNumber, 13)) testLabels = [] for data in myMat: if random.randint(1, 10) <= 10 * trainRatio: trainMat[trainIndex] = data trainLabels.append(labels[index]) trainIndex += 1 else: testMat[testIndex] = data testLabels.append(labels[index]) testIndex += 1 index += 1 trainMat = trainMat[~(trainMat==0).all(1)] # 删除多余的空行 testMat = testMat[~(testMat==0).all(1)]
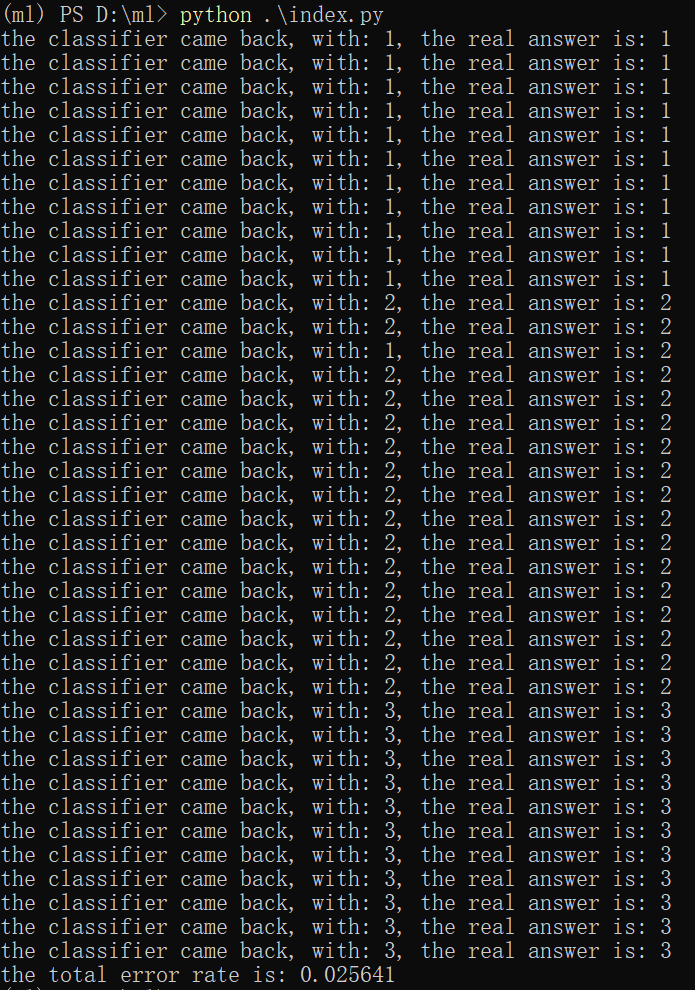
要用kNN算法好像得装scikit-learn,装一个先。再进行训练测试:
1 2 3 4 5 6 7 8 9 10 11
kNN = KNeighborsClassifier(20) kNN.fit(trainMat, trainLabels) predictResult = kNN.predict(testMat) errorCount = 0 index = 0 for result in predictResult: print("the classifier came back, with: %d, the real answer is: %d" % (predictResult[index] ,testLabels[index])) if (predictResult[index] != testLabels[index]): errorCount += 1.0 index += 1 print("the total error rate is: %f" % (errorCount / float(testMat.shape[0])))