前言
kNN的玩法强化练习一下。
数据集准备
here。
数据集处理读取
说是Cross-validation文件,不过我也只是把它当训练测试集用,前面有一些不需要读取的数据可以删掉:
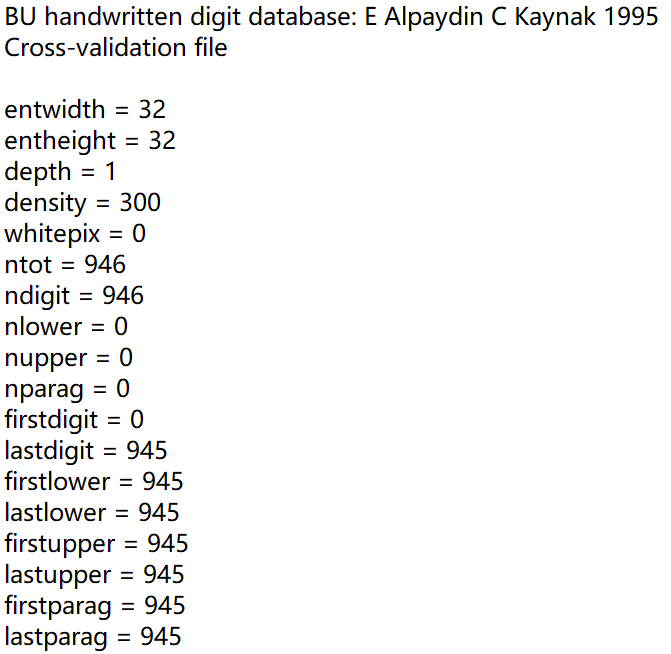
再看数据部分:

可以看到每个数字图片为32x32的大小,最后一行是其标签。
读取数据集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def file2matrix(filename):
f = open(filename)
arrayOfLines = f.readlines()
numberOfLines = len(arrayOfLines)
assert numberOfLines % 33 == 0
numberOfDigits = int(numberOfLines / 33)
myMat = zeros((numberOfDigits, 1024))
labels = []
for x in range(numberOfDigits):
for y in range(32):
for z in range(32):
myMat[x, 32 * y + z] = int(arrayOfLines[x * 33 + y][z])
labels.append(arrayOfLines[x * 33 + 32].strip())
return myMat, labels
|
归一化就不用做了,然后分割训练测试,因为文本中的数据原本就是乱序,所以直接取前70%做训练集:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| trainRatio = 0.7
myMat, labels = file2matrix("E:/dataSet/kNN/optdigits-orig.cv")
numberOfMat = myMat.shape[0]
numberForTrain = int(trainRatio * numberOfMat)
numberForTest = numberOfMat - numberForTrain
kNN = KNeighborsClassifier(8)
kNN.fit(myMat[:numberForTrain], labels[:numberForTrain])
predictResult = kNN.predict(myMat[numberForTrain:])
errorCount = 0
index = 0
for result in predictResult:
print("the classifier came back, with: %d, the real answer is: %d" % (predictResult[index] ,labels[numberForTrain + index]))
if (predictResult[index] != labels[numberForTrain + index]):
errorCount += 1.0
index += 1
print("the total error rate is: %f" % (errorCount / float(numberForTest)))
|
最后结果:
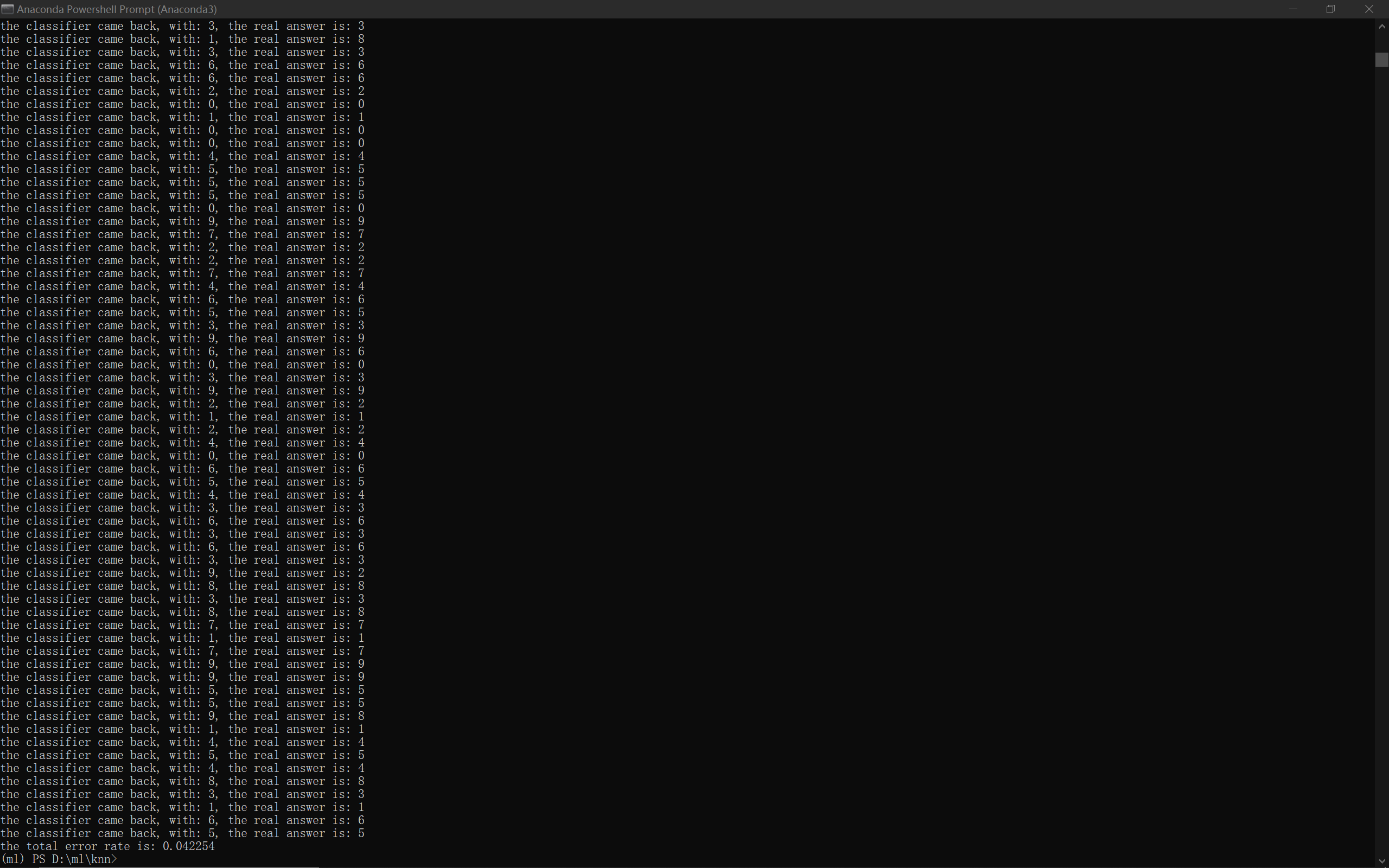
大概有95.8%的准确率,还行。
后记
这个数据集有900多个样本,kNN处理速度还行。