前言
好玩的!
环境搭建
按官方教程来就行了。
测试
先不管怎么做数据集怎么训练,用别人训练好的模型玩一玩先。
从B站下载一个杂谈视频的音频准备处理一下作为输入音频,方法很多,然而我用油猴脚本总是有问题,最后用了唧唧 Down,UI挺好的,似乎也没有捆绑软件,最后下载到一个MP3的音频文件:

虽然不需要从视频中导出音频,但是音频太长了,还是需要一个分割音频的工具,然而Adobe mediaencoder只有试用版,所以最后还是安了个格式工厂,切割一下音频,十分钟一段,可能稍微有点大:
再来个降噪工具spleeter,没降噪的音频效果很差。
现在还不需要制作字幕训练模型,直接运行MockingBird加载模型和音频就行:
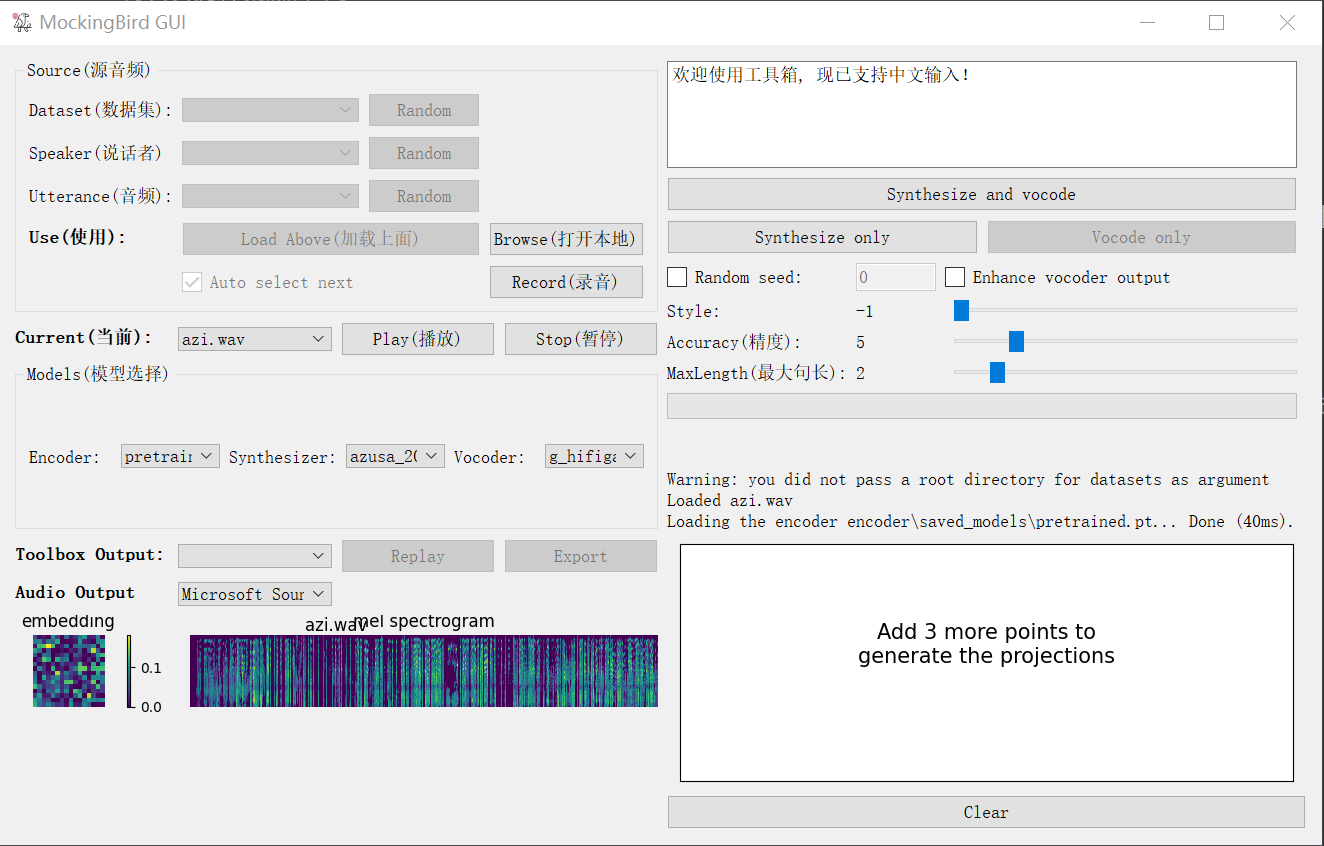
玩了一下,感觉可能是输入音频太长太乱的问题,效果一般。
数据集制作
首先要把这些音频文件都拖出来重命名好:
# -*- coding:utf8 -*-
import os
import shutil
import re
rootDir = "E:/SpleeterGUI/output/"
for dir in os.listdir(rootDir):
dir = rootDir + dir
if os.path.isdir(dir):
fileName = re.findall("E:/SpleeterGUI/output/FormatFactoryPart([0-9]+)", dir)[0]
shutil.move(dir + "/vocals.wav", rootDir + "az" + fileName + ".wav")
print "Clear"
跟前面的步骤差不多,在降噪之后要配上字幕才能开始训练,这里用的是语音识别软件Videosrt,GitHub上的下载链接好像被百度智能云给ban了下不到了。
Videosrt需要用到阿里云的语音识别功能,要去阿里云开一个。有时候会有奇怪的报错,再跑一次报错又没了,有时候又不行,搞不懂,干脆把那个片段删掉算了。然后一个个进行语音识别:
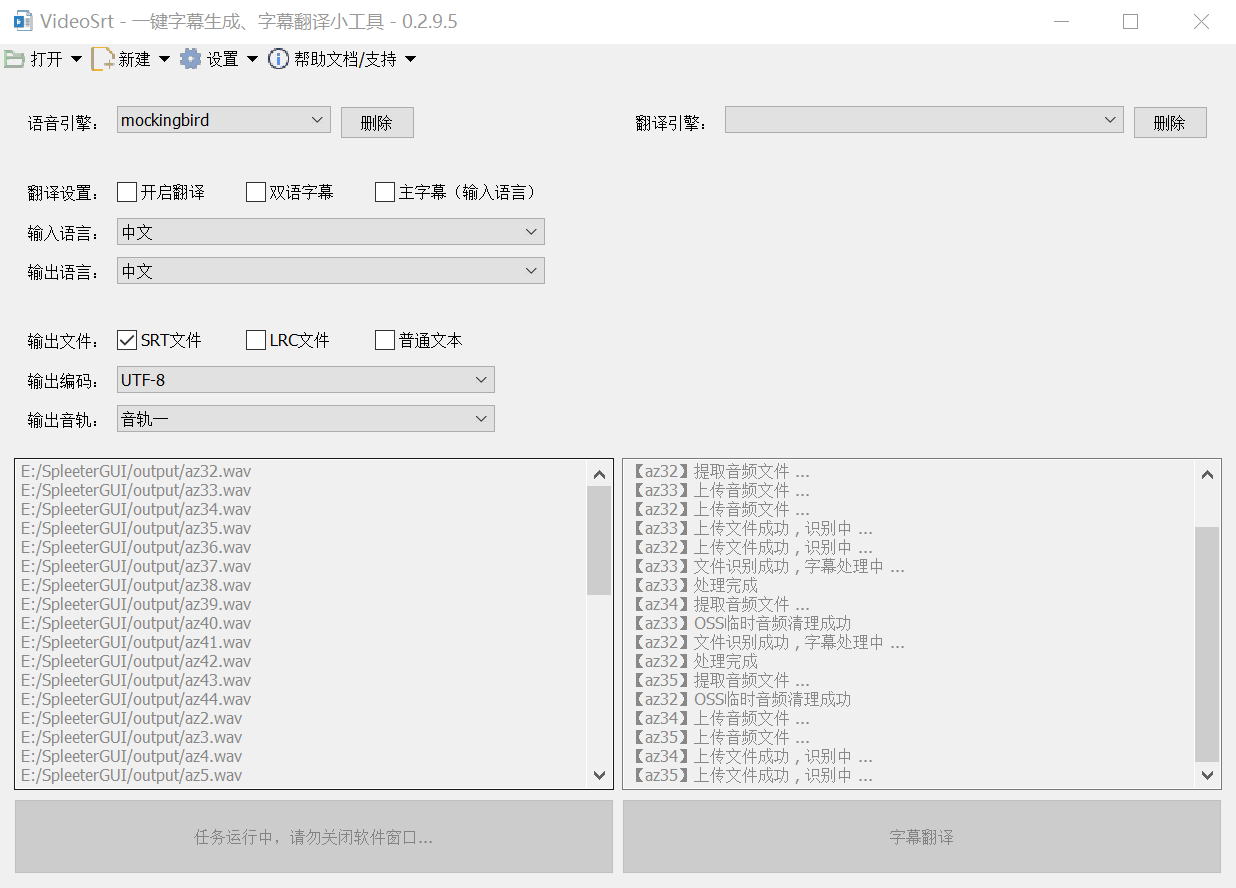
变成这个样子:
然后下载sound_file_processing,用conda给它安个环境安依赖,再按照字幕切割音频成句子:
python .\long_file_cut_by_srt.py
这个文件有点小问题,遇到识别失败,没有字幕只有时间戳的地方就会出错,要修一下。
下一步,对语音识别得到的字幕进行人工修正,有点麻烦的。一共1700条左右,简单得修了500条,先去训练看看效果。
训练模型
首先预处理:

开始训练:
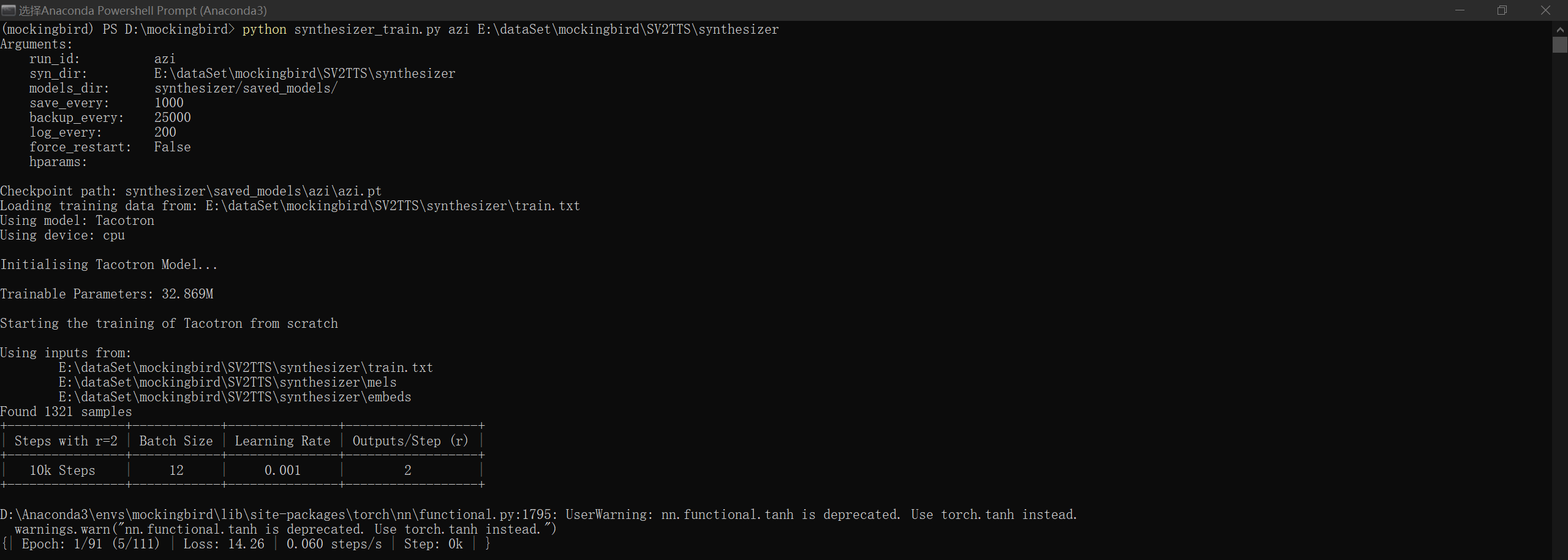
跑了一段时间收敛不了,按照参考视频的做法,下载一个预处理好的合成器模型来用,替换之后继续执行命令。
我的硬件太差了,1k步要跑七八个钟,然而要出结果需要跑几十个k步,难顶。
还是挺好玩的,输入不同的语句音频会有不同的语调产出。