指针分析工具Doop安装与使用
前言
学术们喜欢用的代码分析工具之一,专职指针分析,将代码分析问题转换为图问题进行求解,想要污点分析好像还要自己整,相比之下工程们更喜欢更贴近代码层面功能也更全面的CodeQL。
Datalog
常用于静态代码分析领域的声明式编程语言,由data(谓词,如数据表)和logic(规则,如关系)组成。
原子是Datalog中的基本元素,包括关系原子(类似返回值为boolean的函数调用)和算术原子(常见算式,如a>b)。
1 | |
逻辑的表达形式为:
1 | |
H为结论,B1到Bn为前因,仅当前因为真时结论为真。
逗号(,)代表逻辑与(and &),分号(;)代表逻辑或(or |),感叹号(!)代表取反。
如以下关系推定:
1 | |
枚举Age表中的所有数据,如果该条数据的age字段大于18,则其person字段代表的人为成年人。
支持递归结构,为了避免出现无穷结论的情况,Datalog要求前因中的每一个变量至少要出现在一个非取反的关系原子中:
1 | |
为了避免前因结论发生矛盾的情况,Datalog还禁止一个关系与其取反同时出现在前因和结论中:
1 | |
看起来Datalog中有一些已定义的关系,如New(对象实例化)、Assign(变量赋值)、Store(对象属性赋值)、Load(对象属性作为赋值语句的右端)等。
使用这些关系定义新的便于分析的关系(如代表变量指向的VarPointsTo可以由递归的VarPointsTo和Assign、New等关系组成),借用参考文章里一张有注释的call指令规则图:

完成以下四步:
VCall(l, x, k): 给定调用指令l、调用主体x和调用函数信息k(函数名/参数等)等函数调用信息
VarPointsTo(x, o): 找到调用主体x指向的具体对象o
Dispatch(o, k, m): 根据具体对象o、调用函数信息k找到具体调用函数m
ThisVar(m, this): 获得具体调用函数m中的this变量
可以得到这些结论:
CallGraph(l, m): 调用指令l到具体调用函数m之间存在调用路径
Reachable(m): 具体调用函数m在程序流程中可达
VarPointsTo(this, o): 将具体调用函数m的this变量设置为具体对象o,以后可能可以用来避免父子类困扰
call指令后续还有传递参数(Datalog会先找到实参ai指向的具体对象o,再将形参pi也指向o)和传递返回值(找到具体调用函数m的返回值ret指向的具体对象o,再让接受返回值的变量r也指向o)两条规则,和完整的项目分析、污点分析等内容,就不多说了。
安装Souffle
Souffle是Datalog的高效实现之一,主要用于图可达性求解,可以用于Java下的语言分析、污点分析、安全检查等方面。
但是它不支持Windows,只能用虚拟机来装了,最好挂上代理如proxychains,不然可能会有网络问题。
1 | |
结果:
1 | |
看起来脚本完成了apt库的添加,然后直接apt安装:
1 | |
简单的例子
官方文档中的简单例子example.dl:
1 | |
第一段定义了从输入事实中获取的edge(边)关系,其成员节点为两个number。
第二段定义了path(路径)关系,并将其输出。
第三段定义了路径的推导方式,当两个节点间存在边时则该两节点间存在路径,并定义了一个递归推导式令程序可以推导更长的路径。
创建一个输入文件edge.facts(每行数据各成员之间以制表符分隔):
1 | |
代表节点1和节点2、节点2和节点3之间各存在一条边。然后运行命令:
1 | |
-F和-D选项代表输入输出目录,可以在path.csv推导结果输出文件中看到推导出来的几条路径:
1 | |
变量指向分析
同样是一个简单的例子,其待分析代码如下:
1 | |
我们手动分析将其写入facts事实文件中:
1 | |
简单来说就是由对象实例化、赋值和对象属性组成的一小段代码。其Souffle代码如下:
1 | |
第一段定义了var、obj、field三种关系成员类型为符号类型。
第二段定义了assign、new、load、store关系并从输入文件读取事实。
第三段定义了alias关系(assign以及store再load)和pointsTo关系(new以及alias且pointTo)并输出,
其推导结果如下:
1 | |
安装Doop
了解了Datalog和Souffle,接下来就开始安装和试用Doop了。
Doop是Datalog规则下的多种分析的集合,使用Souffle作为默认引擎。
首先需要安装Java,当然也可以去Oracle官网直接下载:
1 | |
装好了Java 8u342,然后从GitHub上下载仓库:
1 | |
运行根目录下的doop程序,它就会开始下载Gradle并编译项目,同样建议挂代理(好像得用proxychains3,很怪),不然下载依赖的时候可能会有问题。
简单的例子
先写一个简单的Java类:
1 | |
然后编译成class文件并打包jar:
1 | |
放到Doop目录下开始分析:
1 | |
仅分析输入jar文件,完成耗时1m20s,结果存放在out/database目录中,也可以在last-analysis目录找到最近一次分析的结果:
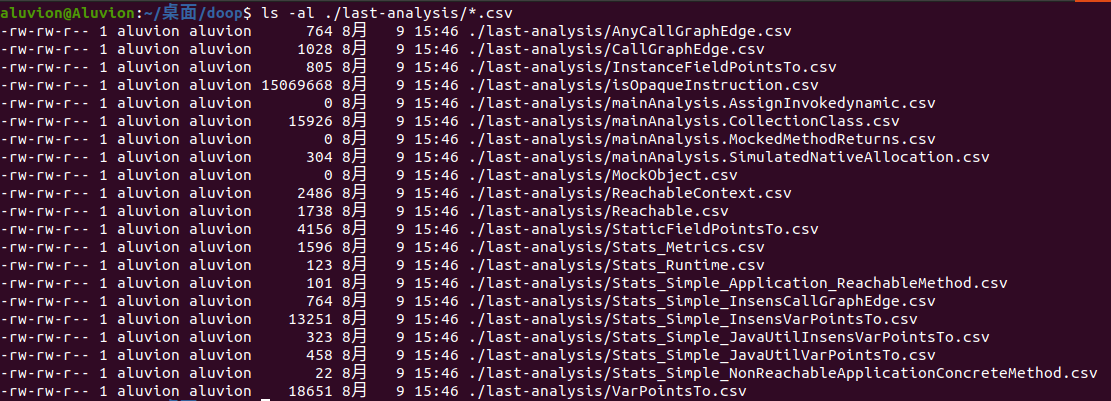
除了解析出来的facts事实文件,还有推导出来的csv文件,如AnyCallGraphEdge.csv:

此外,Doop还有其他很多选项,如上下文敏感、分析模式、最大并行任务数量、反射设定和自定义Datalog规则等等,这里就不多看了。