前言 无。
影响版本 Apache Commons Bcel version < 6.6.0
环境搭建 IDEA新建一个Java项目并添加BCEL的maven依赖:
1 2 3 4 5 6 <dependency > <groupId > org.apache.bcel</groupId > <artifactId > bcel</artifactId > <version > 6.5.0</version > </dependency >
漏洞分析 Java Class文件构造 先弄个看Java字节码的工具,在GitHub上下载jclasslib安装程序 ,或者也可以直接在IDEA里面下载安装扩展。
安装完成后,写一个简单的Java程序并编译成class文件:
1 2 3 4 5 6 7 8 package org.example;public class App {public static void main ( String[] args ) throws Exception{new String []{"cmd.exe" , "/c" , "calc.exe" };
然后使用jclasslib打开文件查看字节码,再用WinHex打开class文件查看原始数据,同时借助bcel的字节码写入函数们进行理解,找到JavaClass类的dump函数,首先是魔数、次版本和主版本信息:
1 2 3 file.writeInt(Const.JVM_CLASSFILE_MAGIC);
一共占8个字节,在WinHex中可以看到原始数据:
在jclasslib中可以看到具体的意思:
魔数意味不明,可以看到,次版本为0,而且应该是由于pom.xml中的编译配置为1.7,所以这里的主版本为1.7。
然后bcel开始写入常量池:
1 2 3 4 5 6 7 8 9 10 for (int i = 1 ; i < constantPool.length; i++) {if (constantPool[i] != null ) {
可以看到首先写入了常量的个数,再按顺序调用常量类型相应的写入函数写入常量,值得注意的是实际写入的常量是从下标1开始的,即写入的常量数量比最先写入的常量数量少1。
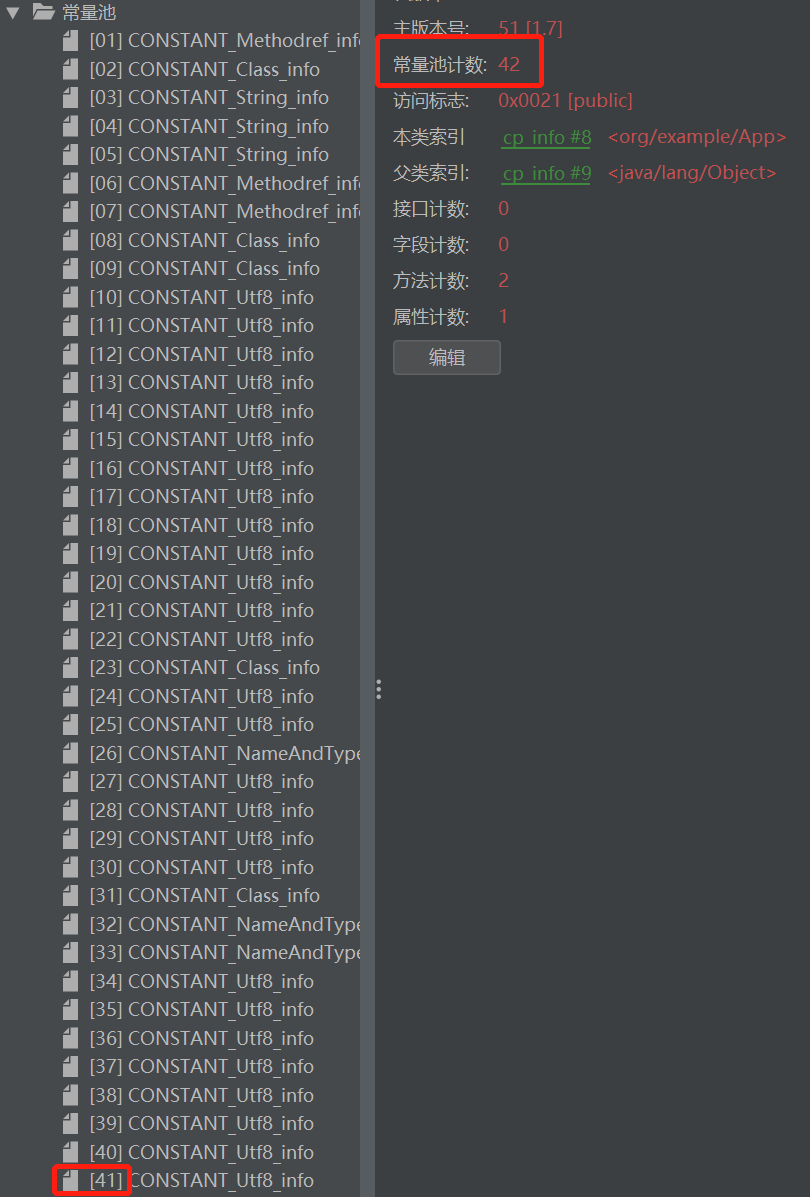
在jclasslib可以看到实际上一共41个常量,而写入的常量数量为42。
而在WinHex中,代表常量数量的short信息占2个字节:
即42,接下来就是第一个常量,常量一般由常量类型 + 数据索引构成。在jclasslib中可以看到其类型为Methodref,在bcel中找到相应的处理类ConstantMethodref类,其类型字节为10:
1 2 3 4 5 public static final byte CONSTANT_Methodref = 10 ;super (Const.CONSTANT_Methodref, input);
写入函数在父类ConstantCP中:
1 2 3 4 5 public final void dump ( final DataOutputStream file ) throws IOException {super .getTag());
除了代表类型的0xa字节外还有两个short类型的数据索引,一共占用5个字节,在jclasslib中可以看到具体代表和指向的数据:
在WinHex中的原始数据则为:
即类型为10,类索引为9,函数名和描述符索引为26。
然后是第二个常量,其类型为Class,写入类为ConstantClass,类型字节为7,写入函数如下:
1 2 3 4 public void dump ( final DataOutputStream file ) throws IOException {super .getTag());
一共占用3字节,包括类型和类名索引,在jclasslib中则是:
WinHex中的原始数据:
然后就是把剩下的常量们一个接一个地写下去了。
找到jclasslib显示的最后一个常量:
1 01 00 28 28 5 B 4 C 6 A 61 76 61 2 F 6 C 61 6 E 67 2 F 53 74 72 69 6 E 67 3 B 29 4 C 6 A 61 76 61 2 F 6 C 61 6 E 67 2 F 50 72 6 F 63 65 73 73 3 B
即长度为40代表exec函数调用名和描述符的字符串。回到JavaClass类,看看写完常量之后写什么:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 file.writeShort(super .getAccessFlags());for (final int interface1 : interfaces) {for (final Field field : fields) {for (final Method method : methods) {
可以跟WinHex中的原始数据对上,就是类描述符、本类索引、父类索引、接口、成员和成员函数等数据。
总结一下,class文件中的常量、接口、成员和成员函数等数据由于数量不定,所以都会在开头写入一个代表数量的字节。也就是说如果我们能让这个代表数量的字节小于它的实际写入数量,就会导致数据越界,比如常量数据越界到后面取代了类修饰符等数据。
BCEL 参考参考文章的BCEL构造类的写法,写一个测试用程序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ClassGen cg = new ClassGen ("HelloWorld" , "java.lang.Object" ,"<generated>" , ACC_PUBLIC | ACC_SUPER, null );ConstantPoolGen cp = cg.getConstantPool();InstructionList il = new InstructionList ();MethodGen mg = new MethodGen (ACC_STATIC | ACC_PUBLIC, Type.VOID,new Type [] { new ArrayType (Type.STRING, 1 ) },new String [] { "argv" }, "main" , "HelloWorld" , il, cp);for (int j = 0 ; j < 65500 ; j++) {"name" + j, Type.STRING, null , null );int name = lg.getIndex();new ASTORE (name))); "HelloWorld.class" );
一个忠告,不要写在IDEA打开的目录里,不然它反编译的时候直接把电脑弄没了。
用jclasslib打开这个class,可以看到里面写入了65520个常量:
然后看一下class的生成流程,这段代码首先调用ClassGen的构造函数新建一个类:
1 2 3 4 5 public ClassGen (final String className, final String superClassName, final String fileName, final int accessFlags, final String[] interfaces) {this (className, superClassName, fileName, accessFlags, interfaces,new ConstantPoolGen ());
这里会调用ConstantPoolGen类的构造函数新建一个常量池:
1 2 3 4 public ConstantPoolGen () {new Constant [size];
常量池被实例化为一个256大小的Constant数组。
然后就是新建函数和65500个变量,调用getMethod整合函数,getMethod函数会调用getLocalVariableTable处理变量表:
1 2 3 4 5 6 7 8 9 10 public LocalVariableTable getLocalVariableTable ( final ConstantPoolGen cp ) {final LocalVariableGen[] lg = getLocalVariables();final int size = lg.length;final LocalVariable[] lv = new LocalVariable [size];for (int i = 0 ; i < size; i++) {return new LocalVariableTable (cp.addUtf8("LocalVariableTable" ), 2 + lv.length * 10 , lv, cp
对于写入的65500个变量调用getLocalVariable函数,其关键代码如下:
1 2 3 4 5 6 7 public LocalVariable getLocalVariable ( final ConstantPoolGen cp ) {final int name_index = cp.addUtf8(name);final int signature_index = cp.addUtf8(type.getSignature());return new LocalVariable (start_pc, length, name_index, signature_index, index, cp
可以看到,这里将所有变量的变量名都作为常量调用addUtf8函数写入到了常量池里:
1 2 3 4 5 6 7 8 9 10 11 12 13 public int addUtf8 ( final String n ) {int ret;if ((ret = lookupUtf8(n)) != -1 ) {return ret; new ConstantUtf8 (n);if (!utf8Table.containsKey(n)) {new Index (ret));return ret;
而代表变量类型的字符串由于常量池已有所以不会重复写入,而由于常量池的初始长度只有256,所以addUtf8函数在写入时会调用adjustSize函数调整常量池大小:
1 2 3 4 5 6 7 8 protected void adjustSize () {if (index + 3 >= size) {final Constant[] cs = constants;2 ;new Constant [size];0 , constants, 0 , index);
超出大小时则将常量池大小*2,这里的size是一个int变量,而我们看到dump函数在写入常量池长度时:
1 file.writeShort(constantPool.length);
写入的是一个short数据而不是int数据,导致上限缩小了,也就是说:
1 2 3 4 5 public final void writeShort (int v) throws IOException {8 ) & 0xFF );0 ) & 0xFF );2 );
short数据只有2个字节,也就是说写入的代表常量个数的数据最多只有2字节长度,即65535个。而实际写入的常量数量却是int类型的,这就导致了一个越界写问题,超出上限的常量会占据后续类修饰符甚至函数字节码的位置。
所以如果能够控制写入的常量,就能通过精心构造越界写入一个存在恶意代码的class文件。
漏洞修复 在6.6.0版本下,ConstantPoolGen对涉及常量池大小的多个地方进行了长度限制,如构造函数里面限制了最大大小:
1 size = Math.min(Math.max(DEFAULT_BUFFER_SIZE, cs.length + 64 ), Const.MAX_CP_ENTRIES + 1 );
又比如adjustSize函数:
1 2 3 4 5 if (index + 3 >= Const.MAX_CP_ENTRIES + 1 ) {throw new IllegalStateException ("The number of constants " + (index + 3 )" is over the size of the constant pool: "
超出上限就会抛出异常。
参考 CVE-2022-42920 BCEL 任意文件写漏洞