Python yolov8学习
前言
学习一下在Windows上搞搞简单的图像识别,由于我的Pycharm环境下有venv独立环境,就不整虚拟环境了。
环境搭建
cuda
据说GPU计算比CPU快,为了用GPU训练模型,需要按照显卡信息找到支持的CUDA版本,在powershell中输入命令:
1 | |
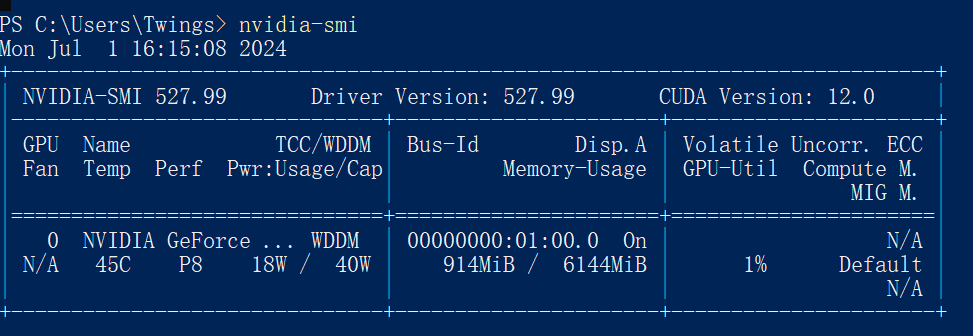
看到我的显卡支持的CUDA最高为12.0:
默认安装,安装到C盘,装完之后看了一眼,占了几个G,也不大。
在powershell中输入命令:
1 | |
看到按照完成:
pytorch
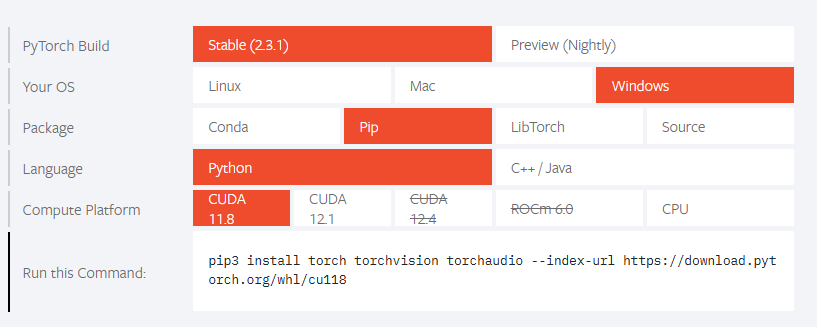
在官方网站上找到安装命令,不过这里没有适合CUDA 12.0版本的,所以安装的CUDA 11.8:
命令:
1 | |
然后等待安装完成。
ultralytics
1 | |
yolov8
在Github上下载yolov8源码,根据参考文章,v8.1.0比较稳定。
下载之后解压,在Github找到权重文件yolov8n.pt,再弄一张测试用图片放到项目根目录,再将整个yolov8源代码目录放到Pycharm项目里面,然后用Pycharm打开。
用一个简单的python脚本测试环境:
1 | |
运行耗时挺短的,结果:
1 | |
在目录下找到结果图片:

参考
Python yolov8学习
http://yoursite.com/2024/07/01/Python-yolov8学习/